deepfacelab是一款非常有意思的人物AI换脸软件,提供丰富的视频素材,用户可以将自己的头像图片上传并替换视频素材中其他人的脸,然后在软件内对脸型处理一下,你可以使用滤镜、美白等功能让自己的脸型看起来更加漂亮,换脸成功后,使你的脸型图片与视频人物图像毫无违和感,人脸融合效果非常棒,几乎可以以假乱真,一点都看不出很假的感觉。使用这款软件,可以通过人工智能技术进行视频换脸,在制作视频过程中,你可以将视频中的人物脸换成你想要的人物脸,它的作用是将视频里面的人脸换成别人的样子,举个例子,视频里面的人是周星驰,你可以把他的脸换成吴孟达的脸,也可以换成你自己的脸,这样是不是非常的有趣。你还在为没有好的换脸软件而苦恼吗?小编推荐你来下载deepfacelab AI换脸软件试试。

使用教程
解压开你会发现软件文件夹内有两个文件夹,和一堆bat批处理指令,下面请看我的介绍:

上图这张图是大概2018年6月的版本的列表,新版和旧版总体bat的功能不会差太多(2019/1/3作者更新了1个新算法,目前群内大神测试没太大用)。
另外你如果玩熟练了你可以自己弄一些拿到前面来,这样会很方便:
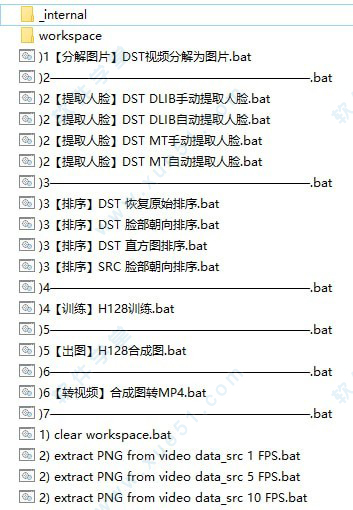
我自己挑出来的这些像排序部分,有些是要自己修改bat内容的。
记住,bat 批处理文件是可以修改的,文件夹里的只是送你的案例而已。
所有软件对应的两边素材:
A即DST 就是原版的视频素材,就是身体和背景不换,要换掉脸的视频
B即SRC 就是要使用到的脸的素材
把两边素材称为A和B的软件,一般都可以互换方向,但是总体操作都是B脸放A上,SRC脸放DST上
DST和SRC素材都可以是图片或者视频
换脸软件的操作是通过SRC脸图集,运算出MDOEL,然后放到DST序列图上,最后把DST序列图连接为视频
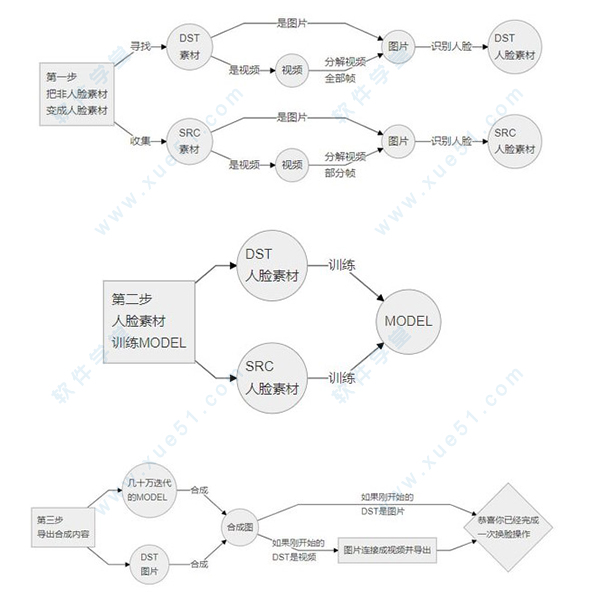
新手操作流程:
【手动】把DST视频放到“workspace”文件夹下,并且命名为“data_dst”(后缀名和格式一般不用管)。
下面步骤的文件目录均在workspace下,如“workspacedata_src”,我将省略为“data_src”
【手动】把SRC素材(明星照片,一般需要700~1500张)放到“data_src”下。
【bat】分解DST视频为图片(需要全帧提取,即Full fps),bat序号3.2 你会看到“data_dst”下有分解出来的图片。
【bat】识别DST素材的脸部图片,bat序号5 有DLIB和MT两种分解方式,一般情况建议DLIB,具体差别什么自己摸索,后面不要带Manual和Debug,这俩一个是手动一个是调试。
【bat】识别SRC素材的脸部图片,bat序号4 具体操作同步骤4。
【手动】第4步和第5步识别并对齐的人脸素材在“data_dstaligned”和“data_srcaligned”内,你需要把这些人脸不正确识别的内容删除,否则影响MODEL训练结果,如果脸图特别小,或者翻转了,那么基本判定为识别错误,但是要说明的是,DST脸超出画面的半张脸需要留着不要删除,SRC脸超出画面基本没用,直接删除吧。
删除SRC错误脸图前可以使用bat序号4.2系列的排序,直方图排序和人脸朝向排序可以较为方便地找出错误人脸,这属于进阶内容,具体不给教程,有需要自己Baidu翻译一下。
【bat】现在你已经有DST的序列帧(图片)素材和SRC的脸部(图片)素材了,你需要运行MODEL训练,bat序号6 一样也是有好多种MODEL,目前建议新手直接跑H128的MODEL(除非你的显卡比较差,那就跑H64)其他MDOEL算法请看GitHub上的介绍。
跑MODEL是可以中断的,在预览界面按回车键,软件会自动保存当前进度,MDOEL文件在“model”文件夹下,不同的MODEL文件名不一样,建议定期备份MODEL,并建议SRC专人专用MODEL
【bat】上面MODEL如果是第一次跑,可能需要10+小时才有合理的效果,结束训练后请运行MODEL导出合成图,bat序号7 这里就根据你的MODEL类型来运行就好了
这里会出现一个问题就是软件会在DOS界面给你好多好多选项,请看下文“导出合成图的选项”。
【bat】导出图片后需要把图片转成视频,那么就运行 bat序号8 就行了,根据你要的最终格式来定。
导出合成图的选项
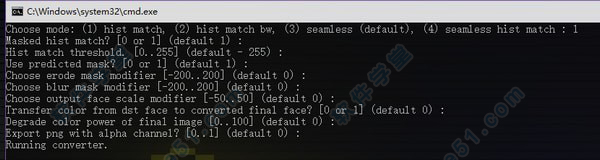
所有选项直接按回车即使用标注的默认选项(default)
第一个问答是问你要哪个合成模式,可以理解为:
1、普通
2、普通+直方图匹配
3、无缝(默认)
4、无缝+直方图匹配
可能每个视频需要的效果都不一样,一般情况我个人建议用:1普通
请注意保留源素材
不论哪款软件,流程结束后建议复制并分类保留:
SRC素材(脸图或原图)
MODEL(丢了就浪费10小时了)
功能特色
1、可单独使用,具有零依赖性,可与所有Windows版本的预备二进制文件(CUDA,OpenCL,ffmpeg等)一起使用。
2、新型号(H64,H128,DF,LIAEF128,SAE,恶棍)从原始的facewap模型扩展而来。
3、新架构,易于模型试验。
4、适用于2GB旧卡,如GT730。在18小时内使用2GB gtx850m笔记本电脑进行深度训练的示例
5、面部数据嵌入在png文件中(不再需要对齐文件)。
6、通过选择最佳GPU自动管理GPU。
7、新预览窗口。
8、提取器和转换器并行。
9、为所有阶段添加了调试选项。
10、多种面部提取模式,包括S3FD,MTCNN,dlib或手动提取。
11、以16的增量训练任何分辨率。由于优化设置,使用NVIDIA卡轻松训练256。
12、安装方便,环境依赖几乎为零,下载打包 app 解压即可运行(最大优势)。
13、添加了很多新的模型。
14、新架构,易于模型实验。
15、人脸图片使用 JPG 保存,节省空间提高效率。
16、CPU 模式,第 8 代 Intel 核心能够在 2 天内完成 H64 模型的训练。
17、全新的预览窗口,便于观察。
18、并行提取。
19、并行转换。
20、所有阶段都可以使用 DEBUG 选项。
21、支持 MTCNN,DLIBCNN,S3FD 等多种提取器。
22、支持手动提取,更精确的脸部区域,更好的结果。
使用技巧
1、 首先把源视频拆分成图片。
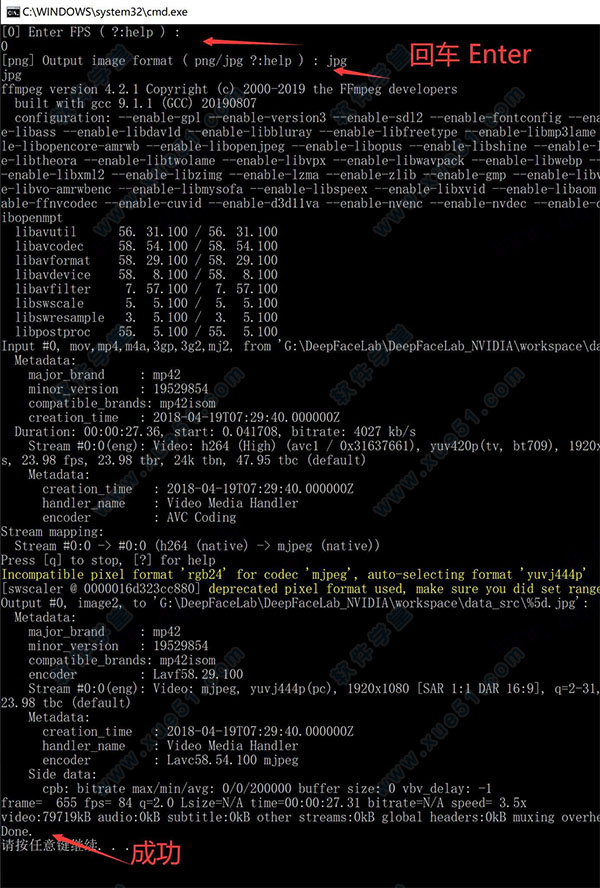
2、开头两个回车,等待,出现Done即表示处理成功。FPS :表示帧率,可以按回车默认,也可以输入一个数字。 Format代表图片格式,可以选JPG或者PNG,默认PNG。
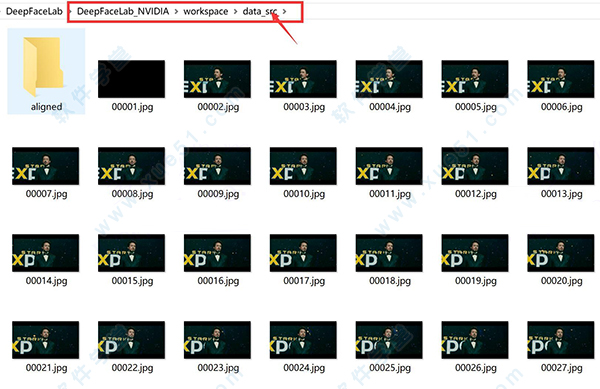
3、处理完成后,data_src文件夹下面会出现很多图片,这些图片就来自data_src.mp4视频。
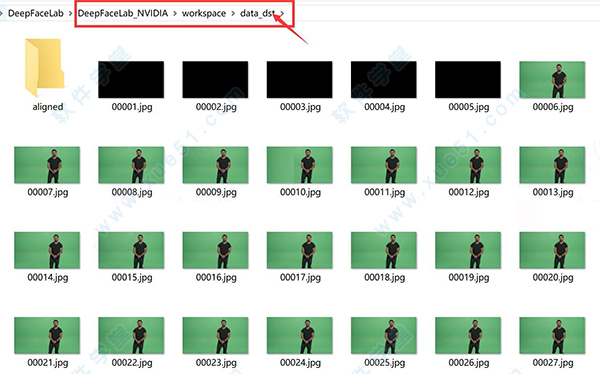
4、一个回车,等待一段时间,看到Done表示结束。
处理完成后,data_dst文件夹下面会出现很多图片,这些图片就来自data_dst.mp4视频。)
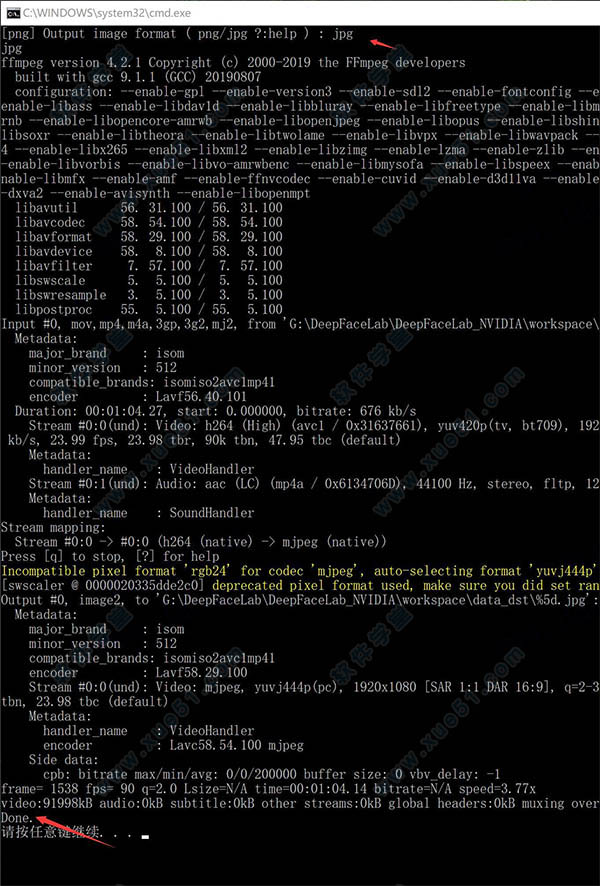
5、两个回车,显示进度条,最后会显示发现的图片和提取到的人脸数量。 GPU index 是针对多卡用户,单卡用户直接回车。 Debug Image 一般不需要,默认回车即可。
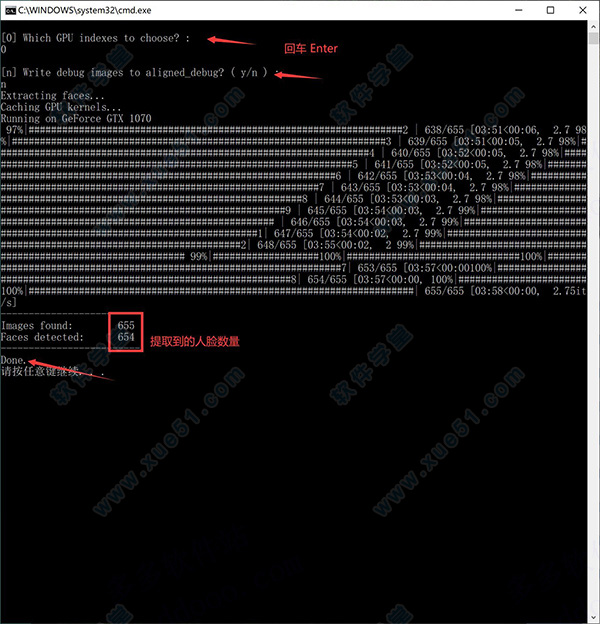
操作成功后,data_src/aligned 文件夹下面会出现唐尼的头像。

6、从目标图片中提取人脸
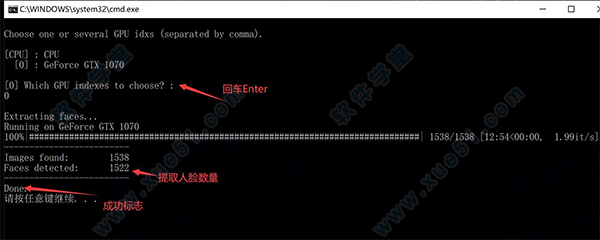
和上一步类似,只是少了一个参数Debug Image,其实是默认就启用了这个参数。

操作成功后,data_dst/aligned文件夹下会出现希亚·拉博夫的人头。在data_dst下面会出现一个aligned_debug文件夹。

deepfacelab配置要求
系统:Win7, Win10
显卡:GTX 1060以上效果较好,需要安装windows 版本的 VS2015,CUDA9.0和CuDNN7.0.5
优点:基于Faceswap定制的bat处理批版本,硬件要求低,2G显存就可以跑,支持手动截取人脸、集成所需要的素材和库文件,功能强大
缺点:复杂、处理批较多,脸部数据不能和其他deepfakes通用,需要重新截取
总结:适合有一定编程基础、追求效率高的用户
常见问题
1、人脸素材需要多少?
尽量不要少,因为它是有限的且需要被替换的素材,根据各软件的脸图筛选规则和网上大神的建议,总体来说,SRC脸图最好是大概700~3999的数量,像该软件的作者,他就认为1500张够了。对于SRC,各种角度、各种表情、各种光照下的内容越多越好,很接近的素材没有用,会增加训练负担。
2、手动对齐识别人脸模式如何使用?
回车键:应用当前选择区域并跳转到下一个未识别到人脸的帧
空格键:跳转到下一个未识别到人脸的帧
鼠标滚轮:识别区域框,上滚放大下滚缩小
逗号和句号(要把
输入法切换到英文):上一帧下一帧
3、MODEL是个什么东西?
MODEL是根据各种线条或其他奇怪的数据经过人工智能呈现的随机产生的假数据,就像PS填充里的“智能识别”,你可以从 https://affinelayer.com/pixsrv/ 这个网站里体验一下什么叫MODEL造假
4、MODEL使用哪种算法好?
各有千秋,一般软件使用H128就好了,其他算法可以看官方在GitHub上写的介绍:https://github.com/iperov/DeepFaceLab
5、Batch Size是什么?要设置多大?
Batch Size的意思大概就是一批训练多少个图片素材,一般设置为2的倍数。数字越大越需要更多显存,但是由于处理内容更多,迭代频率会降低。一般情况在软件中,不需要手动设置,它会默认设置显卡适配的最大值。根据网上的内容和本人实际测试,在我们这种64和128尺寸换脸的操作中,越大越好,因为最合理的值目前远超所有民用显卡可承受的范围。
6、MODEL训练过,还可以再次换素材使用吗?
换DST素材:
可以!而且非常建议重复使用。
新建的MODEL大概10小时以上会有较好的结果,之后换其他DST素材,仅需0.5~3小时就会有很好的结果了,前提是SRC素材不能换人。
换SRC素材,那么就需要考虑一下了:
第一种方案:MODEL重复用,不管换DST还是换SRC,就是所有人脸的内容都会被放进MODEL进行训练,结果是训练很快,但是越杂乱的训练后越觉得导出不太像SRC的脸。
第二种方案:新建MODEL重新来(也就是专人专MODEL)这种操作请先把MODEL剪切出去并文件夹分类,这种操作可以合成比较像SRC的情况,但是每次要重新10小时会很累。
第三种方案:结合前两种,先把MODEL练出轮廓后,再复制出来,每个MODEL每个SRC脸专用就好了。
7、出现ValueError: No training data provided怎么办?
没有脸部数据,可能是你用其它软件截的脸,这是不行的,DFL仅支持自己截的脸。你可以将其它软件截的脸让DFL再截一遍就可以用了
8、出现ImportError: DLL load failed.
首先检查Microsoft Visual C++ distributed 2015 X64装了没有,如果装了就找度娘下载api-ms-win-downlevel-shlwapi-l1-1-0.dll(32位)和ieshims.dll复制到DFL的“_internalpython-3.6.8Libsite-packagescv2”中,
9、为什么我换的脸是模糊的
运存过少,训练时间不够,src人脸过少,loss值太高(0.5以上都有点糊)以及"pixel_loss = True"(就是模糊的开关)都会导致这种情况,虽然512MB可以运行,但是结果肯定是不尽人意的,推荐运存2GB以上,训练时间一般10h以上,loss值推荐0.2左右。
10、为什么训练时loss值显示的是nan,而且马上就报错
这个我也不太清楚,可能是运存太低,解决办法就是“Use lightweight autoencoder? (Y / n,:? Help skip: n):”选择y(轻量编码器,速度快35%,输出结果目前看来差不多)。
11、为什么loss值降到一定就不降了
一般来说降到0.2左右训练就很成功了(一般需要10+h,Iter100000+,而我的电脑需要训练一个星期才能达到目标效果),但是也有特殊情况,降到1左右不再降的可能是脸差的太厉害了,比如讲一个男人的脸贴一个女人身上,当然也有可能是时间不够。
12、src需要多少个照片训练比较好
700~3000个左右,推荐1500个最好,太少的话即使loss降到0.1也是糊的,太多的话加重运算负担。
更新日志
deepfacelab v2018.12.2更新:
1、修复部分系统错误“Failed to get convolution algorithm”
2、修复部分系统错误“dll load failed”
3、修改模型下面的summary文件的格式,显示更多内容。
4、修改脸部遮罩,扩展眉毛部分区域,这个修改不影响Fan-x
5、转换遮罩:为底部区域添加遮罩渐变。

点击星星用来评分