EViews10.0是一款由IHS推出的专业计量经济学软件,新版本还带来了全新的功能和强大的数据接口,支持与云中心连接进行数据的分析操作。而且新版本中开发了一种新的方法来图形化地查看模型中变量之间的关系。颜色编码用于描述模型中的动态,您可以放大和突出变量以使更清晰。
eviews10.0破解版可以广泛地应用于各类经济分析、预测以及模拟领域,而且在联立模型求解上有独特的优势。有需要的朋友可以在本站下载,附有详细的安装破解教程哦!
安装教程
1、首先在本站下载软件压缩包,由于软件体积比较大,小编将压缩包放入百度网盘中,请提前下载好
百度网盘哦
2、之后双击"EViews10Installer(64-bit).exe"进行安装
3、点击"next"
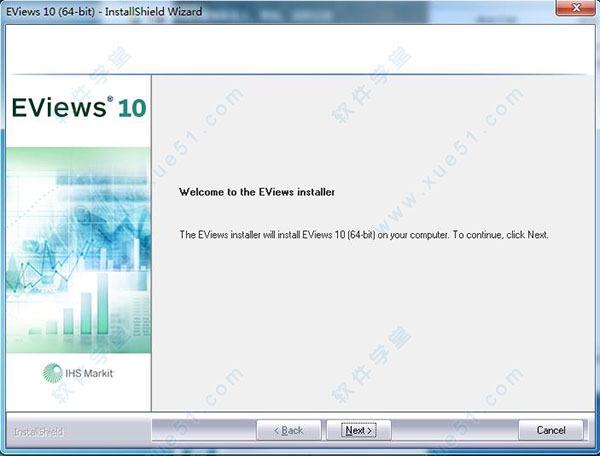
3、接受许可协议,点击"next"
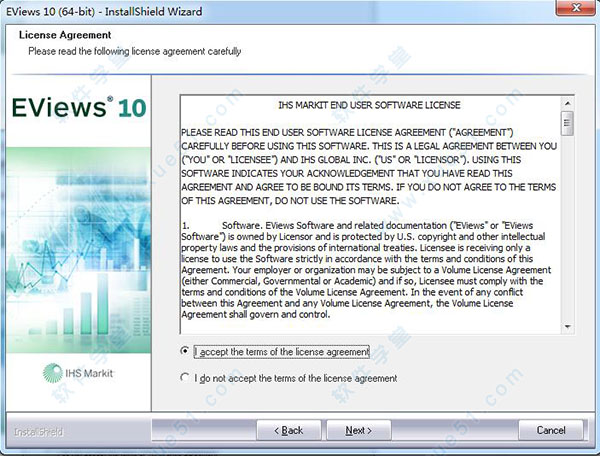
4、选择安装目录
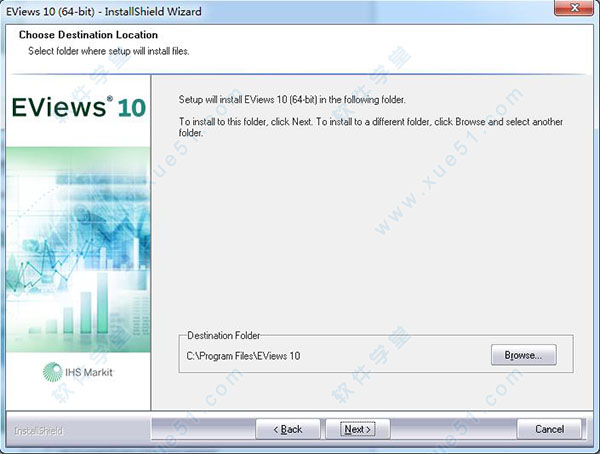
5、在Serial Number一定要填入Demo,用户名可以任意填
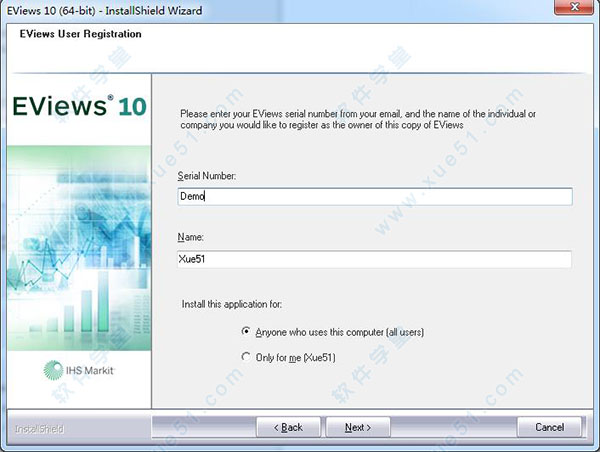
6、选择需要安装的组件,选择默认即可
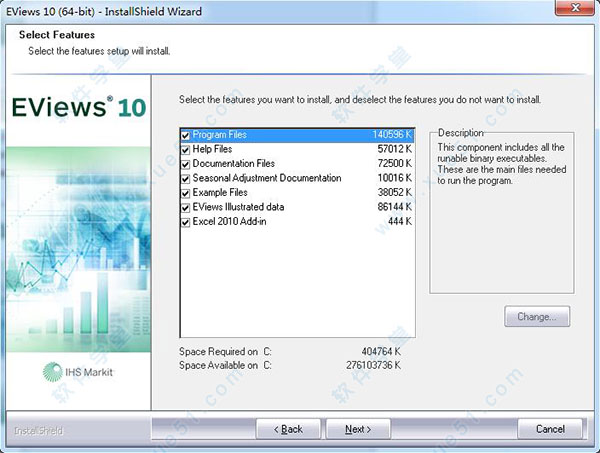
7、这一步一定要选择No,do not allow EViews to……
8、在安装中,等待安装
9、在弹出的小弹窗点击是
10、在桌面创建快捷方式选择是
11、安装完成选择finish结束安装
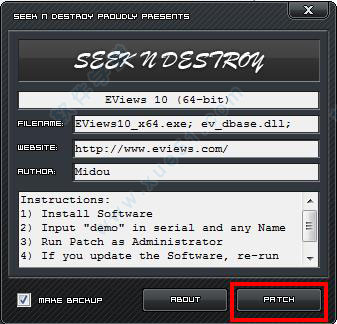
12、将文件夹中的"eviews.10.(64-bit)-patch.exe"复制到安装目录中
13、之后在安装目录中打开,点击"patch",可以看到ok的字样,说明破解成功了
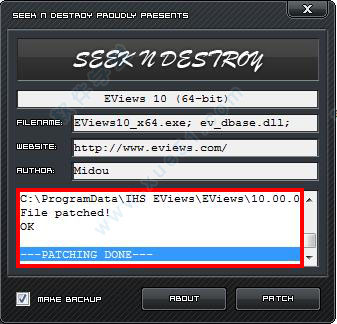
14、最后我们就可以尽情的使用了
功能介绍
1、软件界面
1)自动和用户控制的工作文件历史、快照和备份系统
2)电子表格视图的实时统计信息
3)支持长对象名称
4)增强的日志记录功能
2、数据处理
1)改善了和R.软件的兼容性
2)属性导入和导出
3)与世界银行数据的接口。
4)与联合国数据的接口
5)与欧盟统计局数据接口。
6)保存到Tableau
7)保存到JSON
3、图形、表格和线轴
1)气泡图
2)图表的一系列更新
3)新的默认图样式
4)各种新的图形选项。
5)表格排序
4、计量经济与统计
1)Season-trend分解(STL)
2)MoveReg每周季节性调整。
3)特殊函数的计算
5、估算
1)平滑阈值回归(STR)
2)异方差一致的稳健标准误差选项
3)集群标准误差
4)var和线性限制
5)结构VAR约束的改进
6)VAR历史分解
7)改进的非线性预测
8)附加自回归的分布式延迟(ARDL)工具
6、测试与专业术语
1)VAR结构残差
2)改进的VAR序列相关检验
3)模型边界检查
新功能
1、Workfile Backup Snapshots
提供了重要的界面改进,为您的工作文件提供了一个全新的、功能齐全的快照备份系统。
2、Live Statistics Display
当电子表格第一次打开时,统计数据是使用电子表格中的所有数据来计算的。双击底部栏会弹出一个菜单,显示可以更改的统计数据。最多可同时显示六个统计数字。显示的统计数据也可以通过选项/通用选项来设置…从主菜单,然后是电子表格/实时统计页面。
3、图形的一系列更新
据软件介绍,在新版本中开发了一种新的方法来图形化地查看模型中变量之间的关系。颜色编码用于描述模型中的动态,您可以放大和突出变量以使更清晰。
世界各地的许多中央银行和大公司都使用它构建宏观经济模型,且模型对象是其内部建模经验的核心。且一直为创建、编辑和解决这些模型提供了强大的接口。
为了更方面将数据分析中图标之间的关系解释给外行或者其他同事,方便决策等,新的依赖关系图提供了一个简单的可视化向导,以了解模型中的关系是如何构建的,从而可以演示模型的结构。
4、数据处理
改进的与R连接(兼容性)。以前版本的软件通过第三方程序连接到R。我们发现有些用户在配置这个软件时遇到了困难,在他们的计算环境中工作。 现在直接支持R集成,不再需要第三方软件。
只需在同一台计算机上安装软件和R。
现在支持从Excel和文本文件导入自定义系列属性(以及系列数据)。 已经修改了软件导入向导以支持在自定义系列属性中阅读,这些属性被指定为标题行。
使用教程
如何做相关性分析
利用它做出解释变量的相关系数矩阵1、首先打开软件。建立工作文件。在file下点击new,紧接着点击workfile
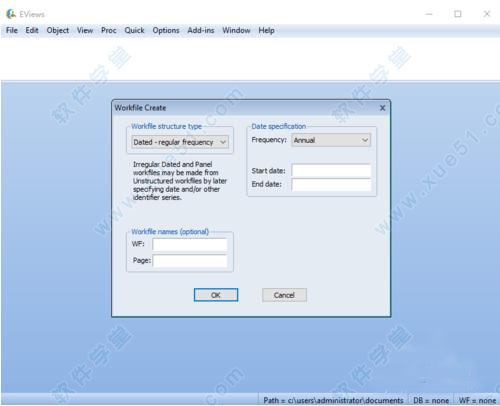
2、这里我们分析的是横截面数据,所以选择“integer date”,在"start date"输入开始的年份,在“end date”输入结束的年份。点击“OK”
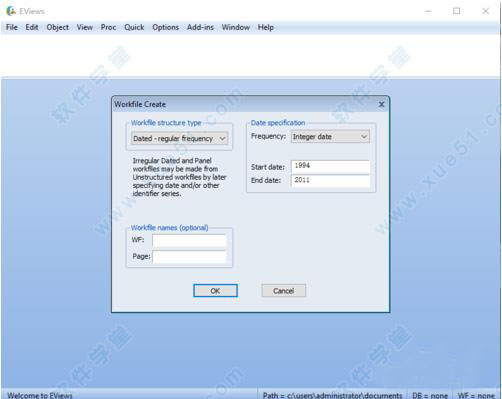
3、接着在“quick”菜单栏中选择“empty group”来建立新的数据组。
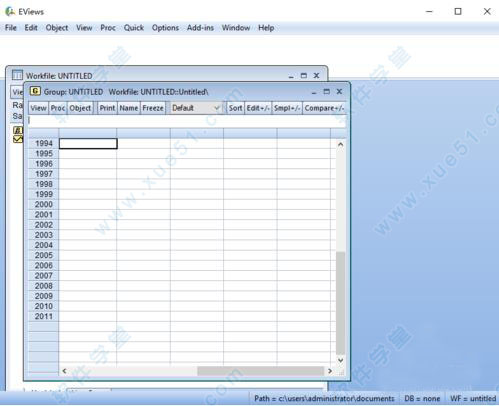
4、将数据录入到软件中,注意此处若想将一列数据命名,可以单击第一空格,然后按“上”方向键。
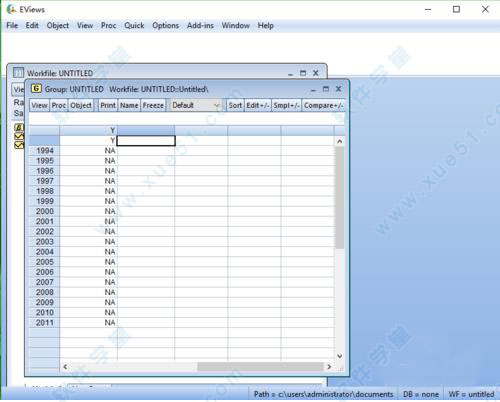
5、根据上一步的方法,依次输入Y,X2,X3,X4,X5来命名每一列的数据。
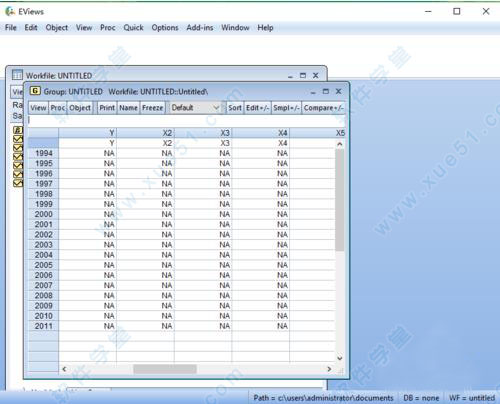
6、录入数据
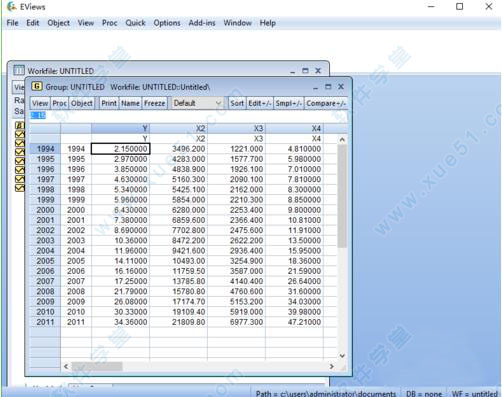
7、选择X2,X3,X4,X5数据:按住"ctrl”用鼠标依次选择数据,点击“open”
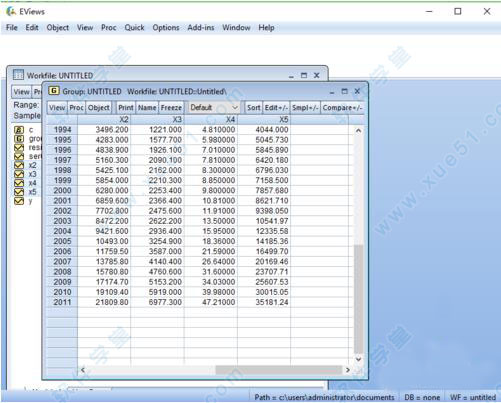
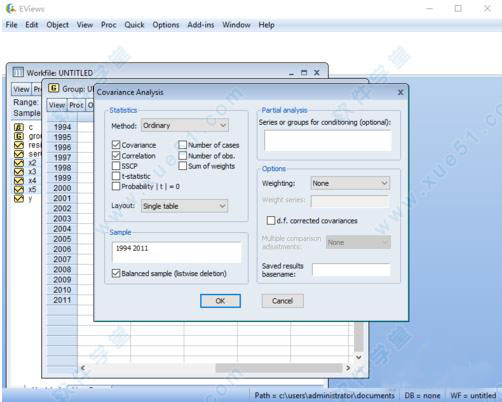
8、点击“view”菜单下的"covariance Analysis"勾选“correlation”选项(左边面板)
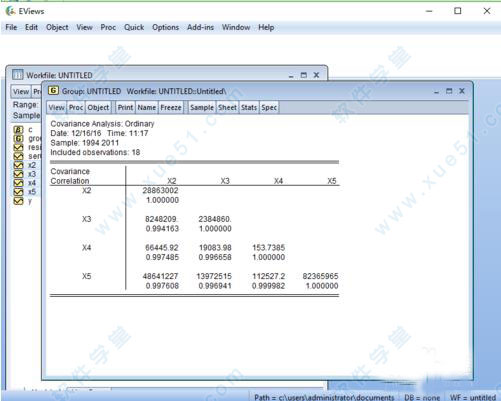
9、点击“OK”,就生成X2,X3,X4,X5的相关系数矩阵啦。根据此矩阵可分析判断各解释变量的多重共线性。
常见问题
1、标准差和标准误的区别在哪?1)概念不同;标准差是描述观察值(个体值)之间的变异程度;标准误是描述样本均数的抽样误差;
2)用途不同;标准差与均数结合估计参考值范围,计算变异系数,计算标准误等.标准误用于估计参数的可信区间,进行假设检验等。
3)它们与样本含量的关系不同:当样本含量 n 足够大时,标准差趋向稳定;而标准误随n的增大而减小,甚至趋于0 .联系:标准差,标准误均为变异指标,当样本含量不变时,标准误与标准差成正比。
2、变异系数到底有啥用?1)简单相关系数:又叫相关系数或线性相关系数。它一般用字母r 表示。它是用来度量定量变量间的线性相关关系。
2)复相关系数:又叫多重相关系数,复相关是指因变量与多个自变量之间的相关关系。例如,某种商品的需求量与其价格水平、职工收入水平等现象之间呈现复相关关系。
3)偏相关系数:又叫部分相关系数,部分相关系数反映校正其它变量后某一变量与另一变量的相关关系,校正的意思可以理解为假定其它变量都取值为均数。 偏相关系数的假设检验等同于偏回归系数的t检验。 复相关系数的假设检验等同于回归方程的方差分析。
可决系数是相关系数的平方。意义:可决系数越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比高。观察点在回归直线附近越密集。
3、如何最快速的输入数据?直接导入啊~~支持多种格式的数据导入,大体操作步骤:点击file-new-workfile。
4、怎么检验异方差?一不小心有了异方差怎么修正?对方程进行回归后,在显示方程的那个界面中,点view,然后点Residual Tests 然后点White heteroskedasticity即可。可以考虑用用resid^-1作为加权,type选择【inverse std.deviation】,weight series输入【1/abs(resid)】。
5、什么是协整分析?通过了协整检验,说明变量之间存在着长期稳定的均衡关系,其方程回归残差是平稳的。因此可以在此基础上直接对原方程进行回归,此时的回归结果是较精确的。

点击星星用来评分