SQL Server是英文Structured Query Language Server的简称,意思为结构化查询语言服务器。这款
SQL Server 2005 64位是美国Microsoft公司在2005年开发和推广的一款功能强大的关系型数据库系统,它最初是由Microsoft、Sybase和Ashton-Tate三家公司共同开发的,并于1988年推出了第一个OS/2版本。近年来不断更新版本,1996年,Microsoft 推出了6.5版本;1998年,7.0版本和用户见面;2000是Microsoft公司于2000年推出,这款SQL 2005 64位是Microsoft公司在2005针对64操作系统推出一个全新版本,具有使用方便、伸缩性好、相关软件集成程度高等优点,结合了分析、报表、集成和通告功能,并为结构化数据提供了安全可靠的存储功能,使您可以构建和管理用于高性能的数据应用程序。无论您是开发人员、数据库管理员、信息工作者还是决策者,软件都可以为您提供创新的解决方案,帮助您从数据中更多地获益。
并且软件用还于大规模联机事务处理 (OLTP)、数据仓库和电子商务应用的数据库平台,也是用于数据集成、分析和报表解决方案的商业智能平台。它包含了各种高度精确的可配置安全功能,使用这些功能,管理员可根据其所处环境的特定安全风险,实现经过优化的深度防御。同时,它还引入了一些“Studio”帮助实现开发和管理任务,组件包括:数据库引擎、Reporting Services、Analysis Services、Notification Services、Integration Services、全文搜索、复制和Service Broker。
该软件是一个全面的数据库平台,使用集成的商业智能 (BI) 工具提供了企业级的数据管理。 数据库引擎为关系型数据和结构化数据提供了更安全可靠的存储功能,使您可以构建和管理用于业务的高可用和高性能的数据应用程序。数据引擎是本企业数据管理解决方案的核心。此外结合了分析、报表、集成和通知功能。这使您的企业可以构建和部署经济有效的 BI 解决方案,帮助您的团队通过记分卡、Dashboard、Web services 和移动设备将数据应用推向业务的各个领域。与 Microsoft Visual Studio、Microsoft Office System 以及新的开发工具包(包括 Business Intelligence Development Studio)的紧密集成使该软件与众不同,是一款值得信赖的关系型数据库管理软件,推荐下载使用。
小编历尽艰辛终于整理出了详细的安装教程,并且提供的是
SQL Server 2005 64位下载,现在分享给大家,希望能够帮助到你,有需求的用户欢迎前来本站下载使用。
SQL Server 2005安装教程
1、下载并解压,得到如下文件。

2、安装软件,它的有些服务要依赖于IIS,所以为了保证数据库的顺利安装,先启用IIS服务吧!Win7比XP好的一点是:启用IIS功能无需借助系统安装盘了,只要在控制面板里启用即可,首先点击“程序和功能”。
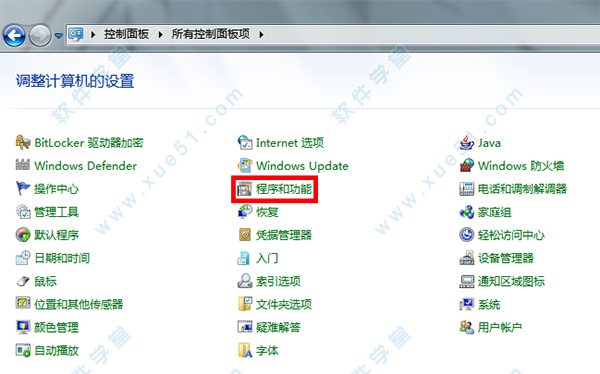
3、接着点击“打开或关闭Windows功能”。
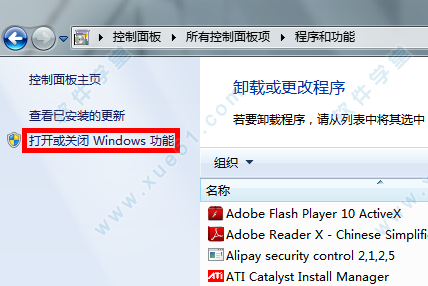
4、需要注意的是,选中红框中的复选项,分别为“Internet Information Services 可承载的 Web 核心”、“Web 管理工具”和“万维网服务”,这里我不确定“Web 管理工具”是否需要,因为我选中它们的父节点“Internet 信息服务”后选中了它的一些子项,多选总比少选全面,需要将它们的子项全部选中才显示为“√”,否则显示为“■”,记住,一定要显示为“√”才行,点击确定后会出现线面的框框。
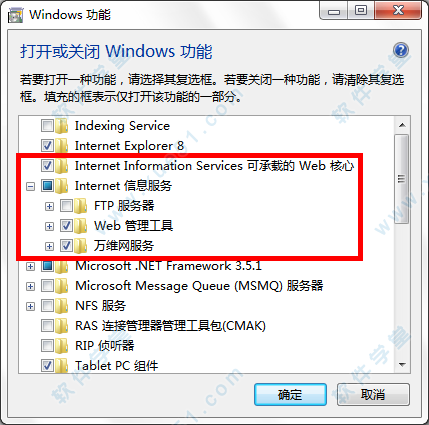
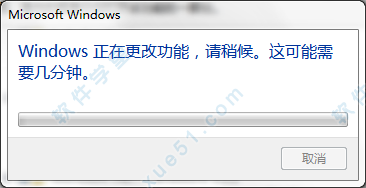
5、Windows正在更改功能,请稍后。这可能需要几分钟,等待安装完成即可。
 PS:如果我们不启用IIS功能,在后续安装时会遇见如下图所示画面。
PS:如果我们不启用IIS功能,在后续安装时会遇见如下图所示画面。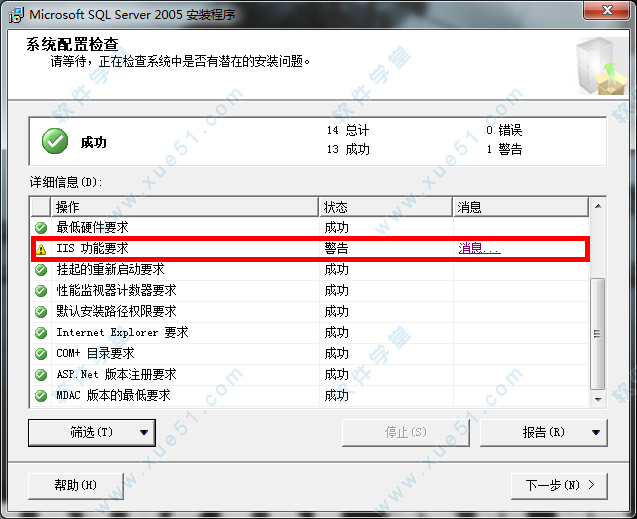
到此,IIS功能就算启用完成了,下面开始安装SQL 。
6、安装文件解压后是一个ISO的镜像,其实是一个DVD文件,将两张光盘合并到一起了,所以你的电脑需要安装
DVDFab Virtual Drive虚拟光驱,本站有详细安装说明。
首先启动
虚拟光驱软件,把SQL的镜像加载进来,如下图所示。
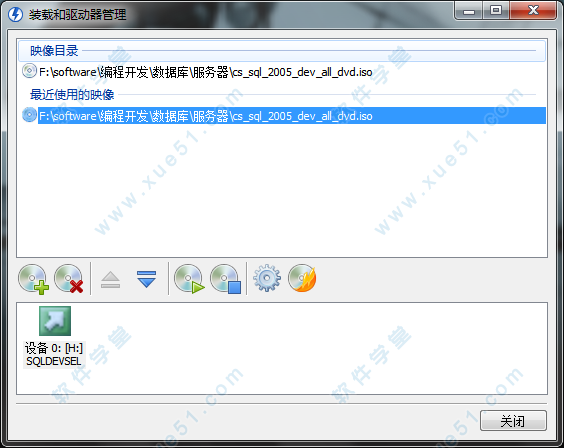
7、接着我们可以在我的电脑里看到这张虚拟的安装盘了,如下图所示。

8、如果没有自动运行,那么我们就点击H盘图标,找到“setup.exe”双击运行。

9、这里选择“基于x64的操作系统(6)”。

10、如果你的电脑曾经完全安装过VS的话,选择“服务器组件、工具、联机丛书和示例”进行SQL 核心组件的安装。

11、接着会弹出兼容性问题,点击“运行程序(R)”即可。
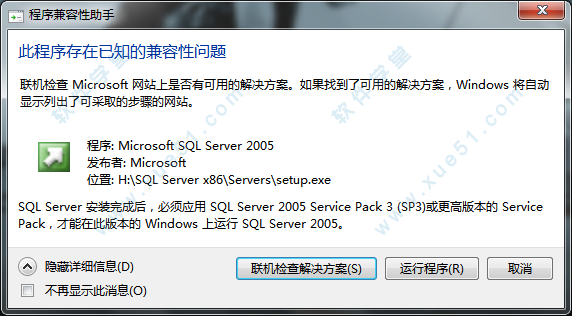
12、在许可协议界面,选择“我接受”这一项,点击“下一步”。
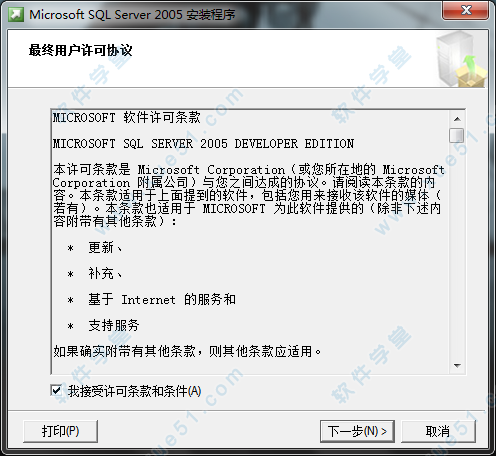
13、安装程序会检查所需组件,点击“安装”。
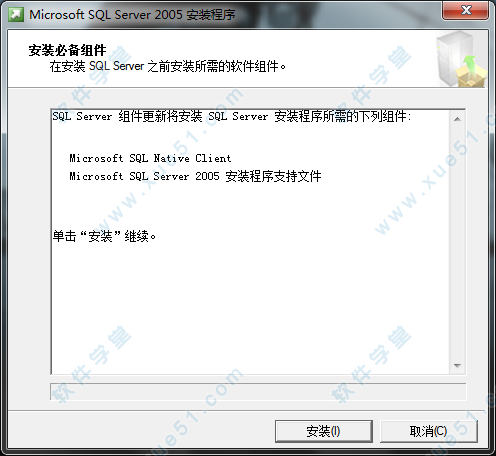
14、安装进行中,请稍后。
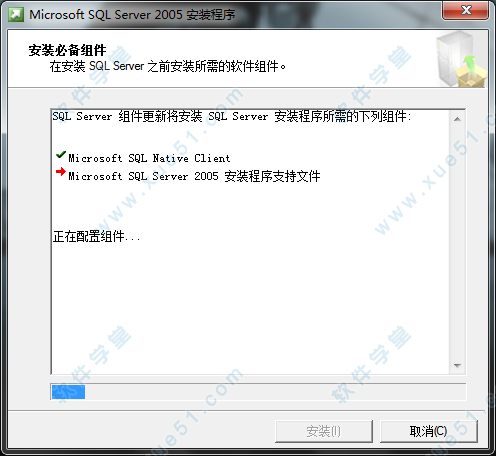
15、安装完成后,点击“下一步”。
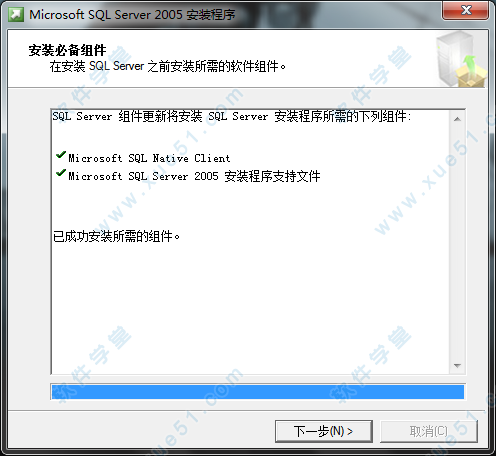
16、接着软件会检查你的系统配置,稍等片刻。
17、紧接着跳转为安装向导界面,点击“下一步”。
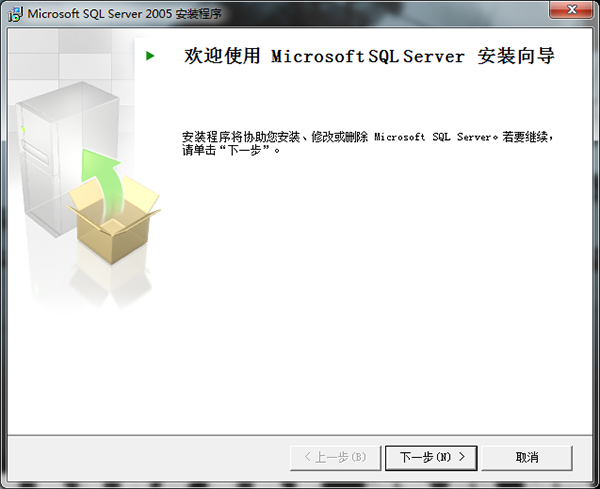
18、这时我们看到,所有的项目都成功,如果之前没有启用IIS功能的话,出现的画面就是之前的那个样子,点击“下一步”。
19、在注册信息界面,输入公司名后,点击“下一步”。
20、这里需要注意,如果你的界面只有最后一个复选框可选,其他都为灰色不可选,那说明你的sql 2005版本有问题,不是开发版,请马上放弃安装,从上面我给的下载地址下载开发板进行安装。全部选中后点击“下一步”。
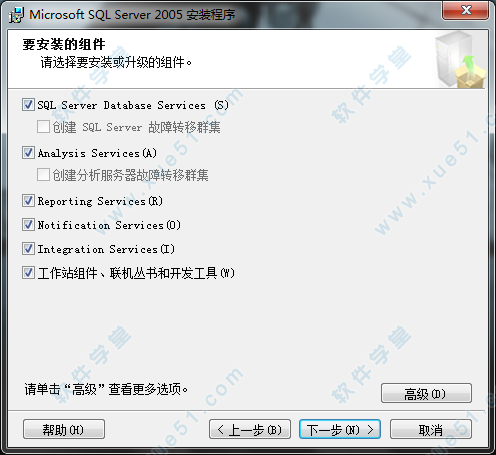
21、默认安装在系统盘下,我们可以点击高级进行修改,点击“浏览(R)”,选择好你想要安装路径。
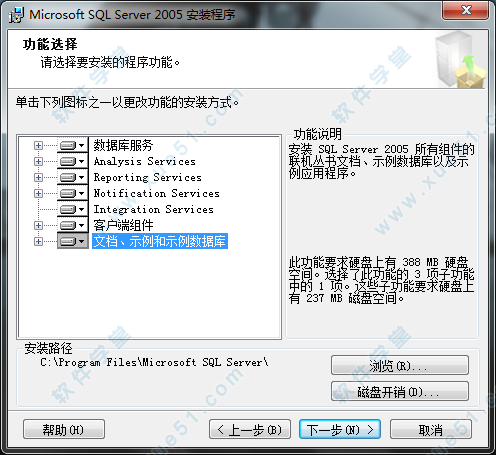
22、小编这里将“C”修改成了“D”,点击“确定”。
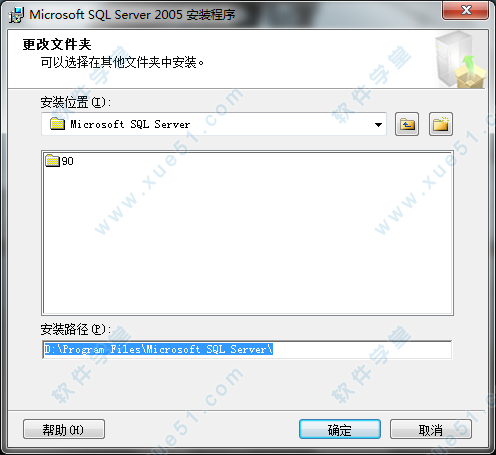
23、请选择需要安装的程序功能,点击“下一步”。
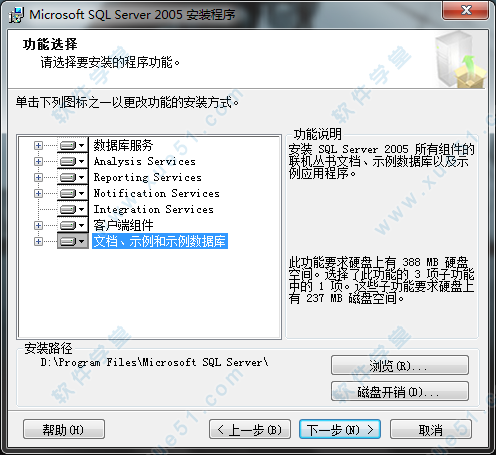
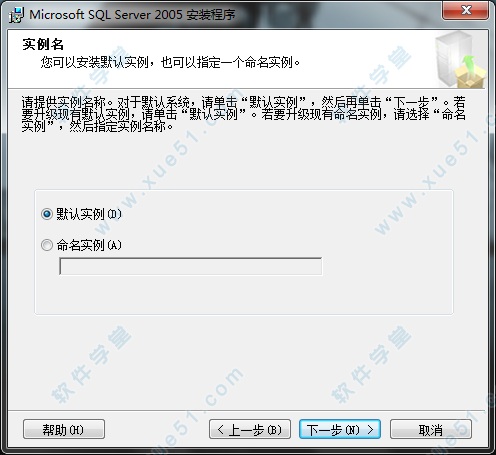
24、这里小编选择的“默认实例”,也可以选择“命名实例”,点击“下一步”。
25、一切默认,直接点击“下一步”。
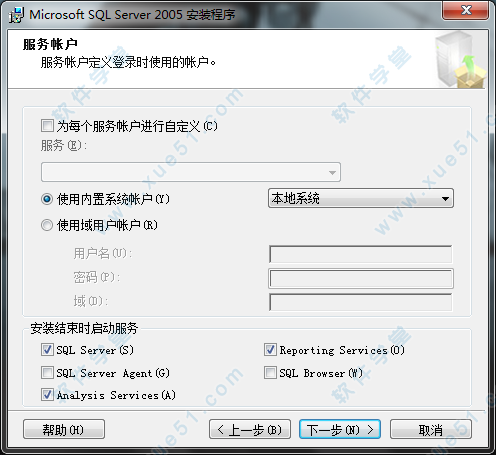
26、因为其他程序也可能连接数据库,所以选择“混合模式”,并键入sa密码,点击“下一步”。
27、默认选项,直接点击“下一步”。
28、默认,点击“下一步”。
29、还是默认,点击“下一步”。
30、确认安装信息,点击“安装”,漫长的安装才刚要开始。
31、安装进行中,需要一些时间,请耐心等待。
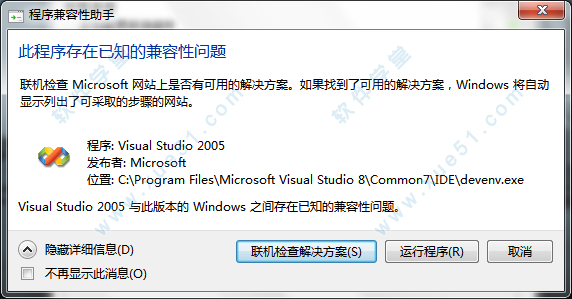
32、安装中途,遇到的第一个弹出窗口,点击“运行程序(R)”。
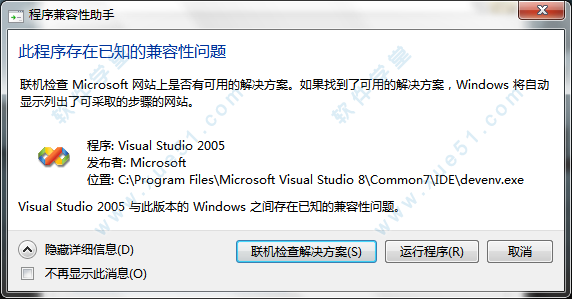
33、安装了一会,结果又弹出,继续点击“运行程序(R)”。
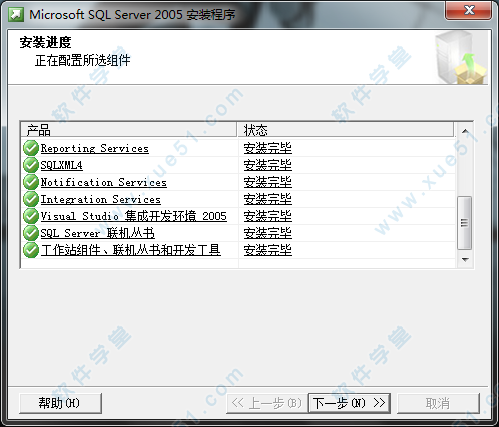
34、所有模块都安装完毕了,点击“下一步”。
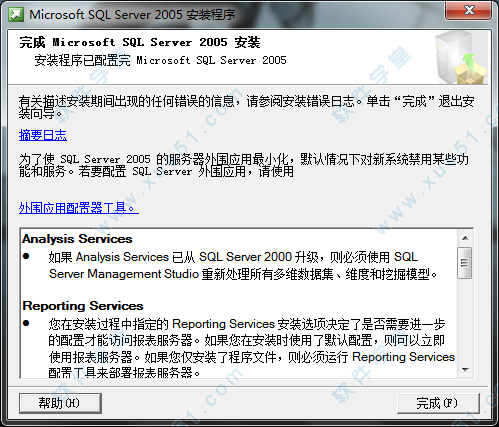
35、到这里就接近尾声了,点击“完成(F)”。
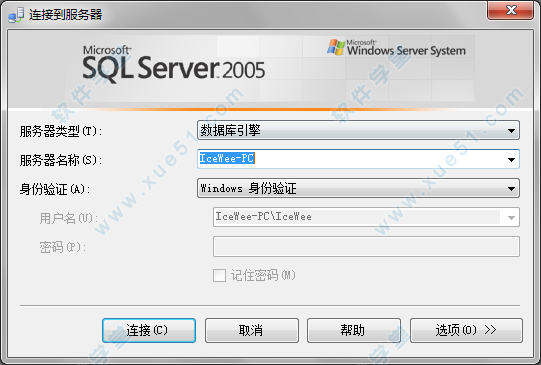
36、这个界面是登陆到刚刚安装的数据库,因为安装的时候我们使用的是“默认实例”,也就是计算机名称,“IceWee-PC”是我的计算机名称,点击连接就登陆到数据库了。
 PS:小编个人感觉安装SQL 需要注意的地方有两点,一是IIS功能的启用,二是一定要选对安装版本,我第一次就下错了,下的企业版,结果就只能安装“工作站组件、联机丛书和开发工具”。
PS:小编个人感觉安装SQL 需要注意的地方有两点,一是IIS功能的启用,二是一定要选对安装版本,我第一次就下错了,下的企业版,结果就只能安装“工作站组件、联机丛书和开发工具”。SQL Server 2005使用教程
1、打开安装好的软件,就会看到登陆页面,选择好自己的服务器名称。选择windows身份验证。然后连接即可登陆数据库。
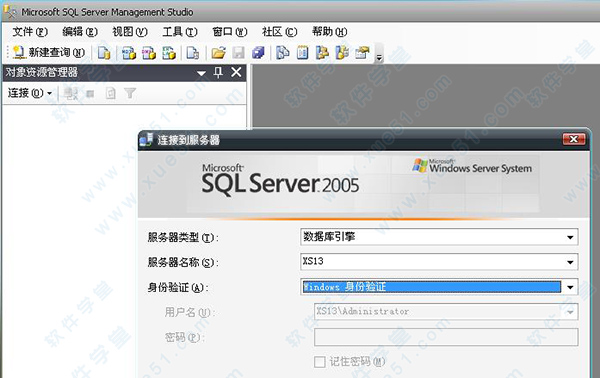
2、进入数据库后,在下图所示,箭头指示的位置。使用鼠标,点击鼠标右键。进入服务器属性。
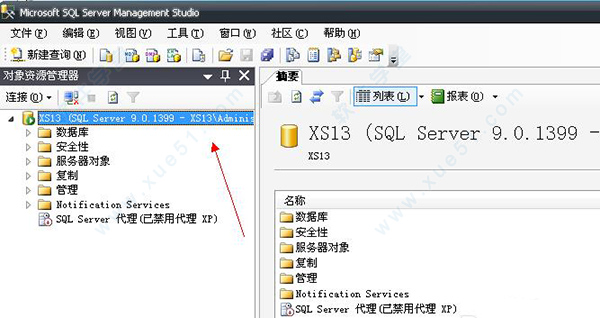
3、在属性界面选择安全性。选中右边的SQL和windows身份验证模式。点击确定即可。
4、在主页面打开安全性,就会看到右边的登陆名。
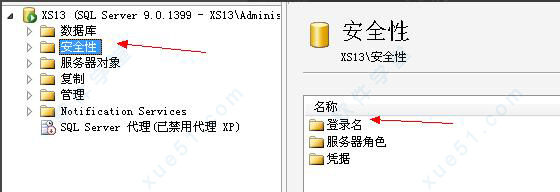
5、在登陆名称内双击 sa。进入sa的属性。
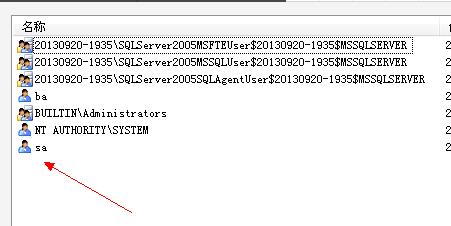
6、在sa属性内重新设置sa的密码。设置完密码点击确定。这时候把窗口最小化。
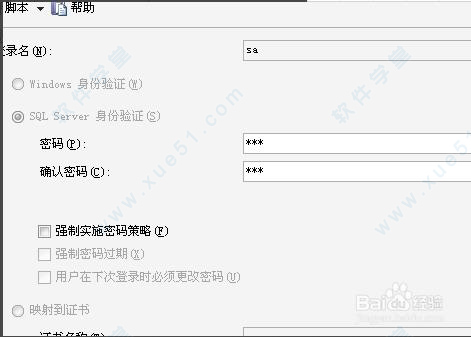
7、打开电脑桌面左下角的开始菜单,如下图所示找到Configuration Manager。
8、打开主页面,找到网络配置里的mssqlserver的协议。就会看到右边的Namedpipes和TCP/IP.把这两个都设置为已启用。
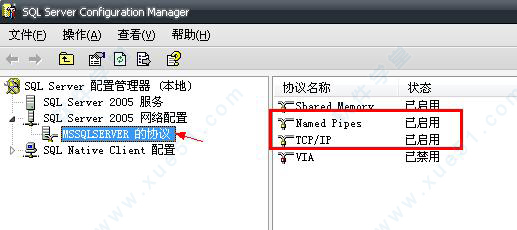
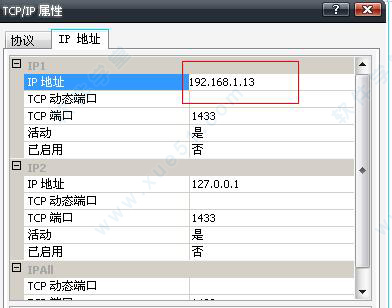
9、然后双击进入TCP/IP属性。在IP地址选项。设置好自己的本机ip地址。注意端口号是1433.。设置好之后点击确定。
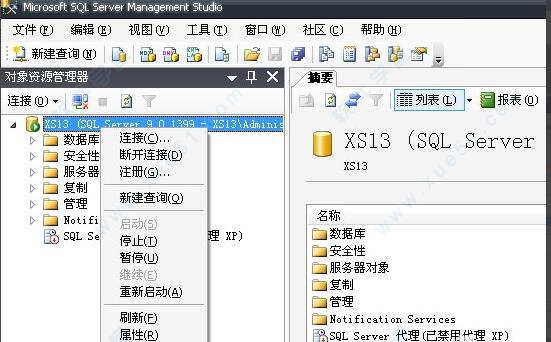
10、打开主页面主页面。在如图所示的位置点击鼠标右键重新启动。
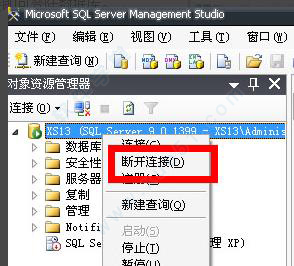
11、以同样的方式再点击断开连接。
12、点击如图所示的连接上点击数据库引擎。
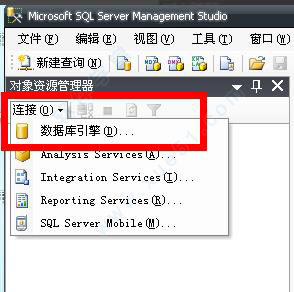
13、这时候进入了登陆界面。在身份验证里选择身份验证。登陆名写成sa,再填上密码。就可以登陆了。
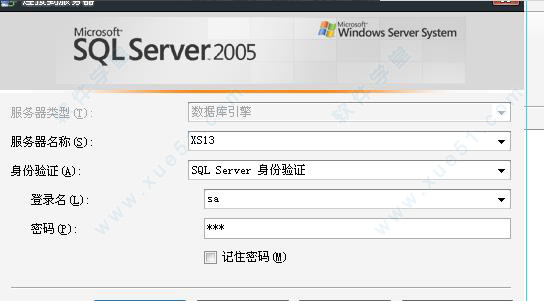
SQL Server 2005如何附加数据库
1、将备份的数据库,复制到你想放的盘符下。记住放的路径。
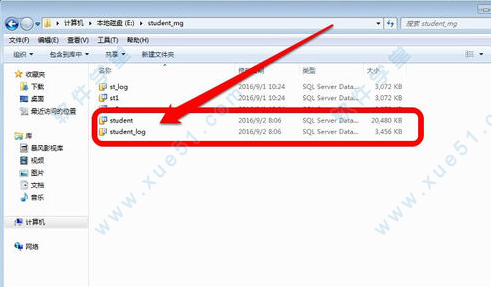
2、打开电脑上安装的软件,毫不犹豫的登录进去。
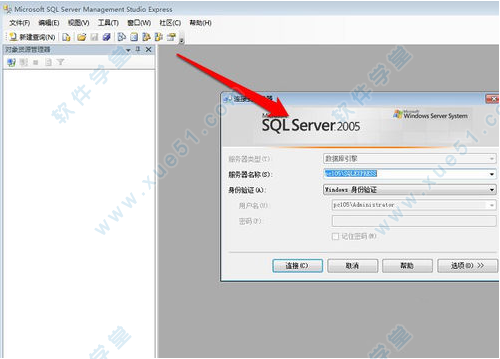
3、在左侧找到数据库文件夹,右键->任务->附加。
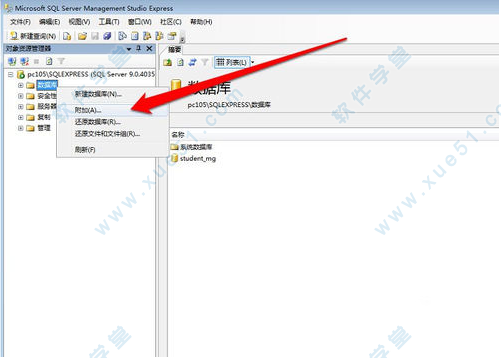
4、在右侧有一个添加按钮,点击后选择备份的数据库文件。
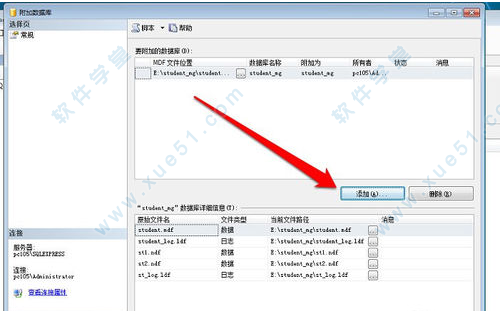
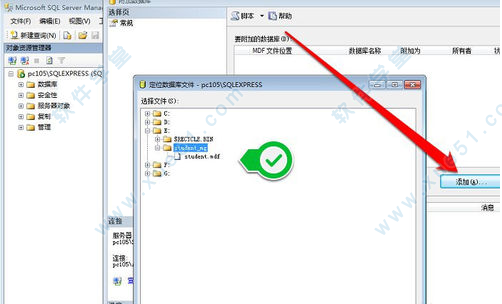
5、选择备份的数据库文件后,确定附加数据库。
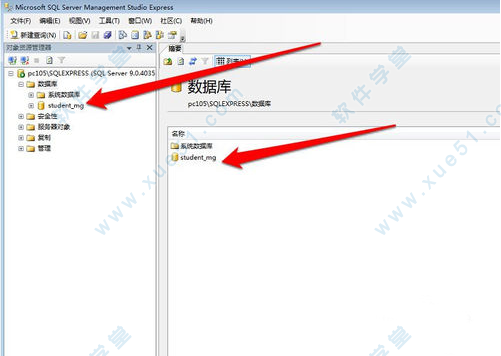
6、这时,就进入这个画面,你就可以看到你添加的数据库已经附加成功。
SQL Server 2005如何物理恢复
1、首先连接上数据库后 右键单击要操作的数据库名选项 依次选择任务-》备份。
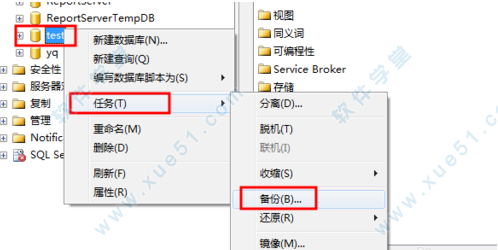
2、这里你可以选择备份类型,自定义备份集名称选择过期时间以及磁盘目录路径等信息 如图所示,根据你的需要选择。
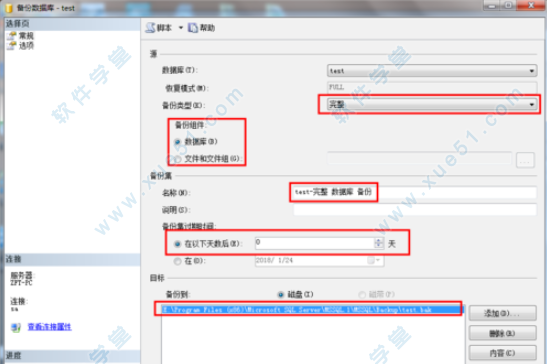
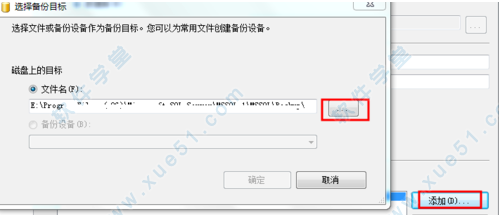
3、如果要修改备份的磁盘路径信息 点击添加按钮后在弹出框选择如图所示的按钮选择文件夹后点击确定即可修改成功。
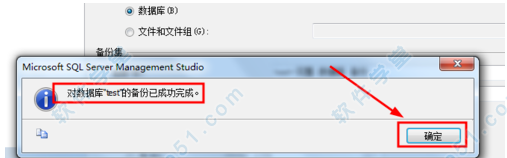
4、做好各项选项的设置后 点击底部的确定按钮等待一会就会弹出如图所示的窗口 即备份成功了。
5、恢复操作 也是单击数据库名选项 依次选择任务--》还原--》数据库选项 如图所示。
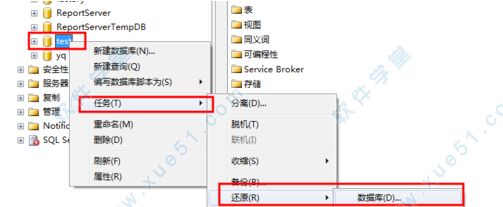
6、这里选择要用于还原的备份集也就是刚刚我们备份的数据哦 如果有多个勾选一个即可。
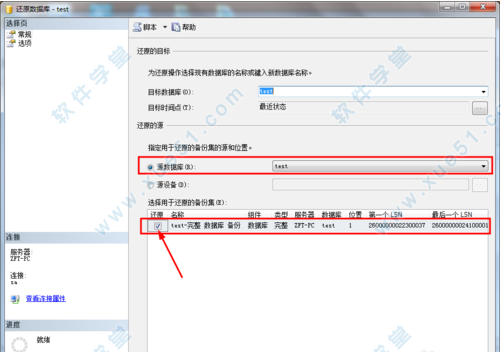
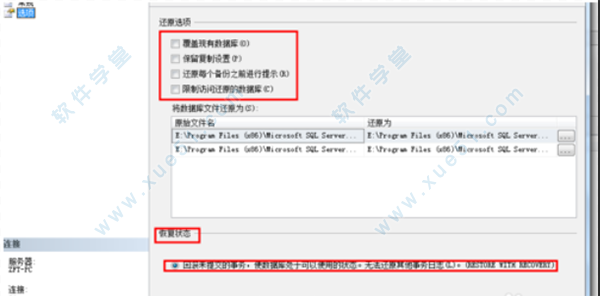
7、然后点击左侧的选项按钮如图所示 可以选择还原选项以及恢复状态,这里选择默认(提示一下,如果遇到还原失败的情况,勾选还原选项中的第一个覆盖现有数据库选项即可)。
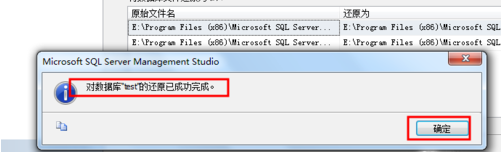
8、点击确定按钮后会进行恢复操作,如图所示是恢复完成的提示,结束。
如何查看用户名密码
sp_helplogins 查看所有用户信息,不过密码是加密过后的,看不了的 用“SQL Server Management Studio”,以“windows身份验证”进入,在“安全性”->“登录名”,找到 登录用户(sa),按右键进入去修改 该用户(sa)的 密码。
SQL Server 2005如何导出数据
方法/步骤
第一步:查看需要备份的数据库登入SQL Management Studio后,在右侧打开树状图可以看到相关数据库。
第二步:数据库脱机选中需要备份的数据库后,选中“任务”->“脱机”,脱机时候,必须关掉表、查询等。
第三步:确认脱机成功脱机这一步很重要,因为不脱机,直接复制这两个文件会报错,所以必须得脱机。请确保出线一下提示界面,才能保证脱机成功。
第四步:复制备份文件进入数据库安装目录,相对位置如“Microsoft SQL ServerMSSQL.1MSSQLData”文件夹,在这个文件夹内,选择你要复制的数据库文件(.mdf和.ldf),然后粘贴到你需要备份的地方即可。
SQL Server 2005如何导入数据
方法一:可以用导入导出。看下SQL2005都支持那些格式的导入(例如EXCEL),然后在SQL2005把你想要导出的表导出到那种格式,最后在SQL2005导入。
方法二:可以用所有任务Tasks的脚本Generate Scripts。在你想要导出数据的数据库右击鼠标所有任务、脚本然后按向导一步步往下最后完成。不过要注意的是在set scripting options步骤中的save to file 选项的files to generate 如果你这10张表比较小可以按默认的single file ,比较大的话(像大于50M)就选择single sille per object ,然后点击右边的高级选项Advanced 在弹出窗口中有一项是tyoes of data to script 注意要选择schema and data选项,还有一项是script for server version 这选项选择SQL 2005。最后找到你所保存的脚本路径,在SQL2005上当平常语句执行就可以了。(注意SQL2005是否有有那个数据库)
如何删除数据库日志文件
使用时间长了,日志文件会很大,占用过多系统资源,数据库可能会报 log full 的错误,甚至磁盘空间占满让数据库处于不可用状态,这个时候我们需要清理数据库:
清理数据库日志可用两种方法:
方法一:清空日志。
1、打开查询分析器,输入命令DUMP TRANSACTION 数据库名 WITH NO_LOG
2、再打开企业管理器--右键你要压缩的数据库--所有任务--收缩数据库--收缩文件--选择日志文件--在收缩方式里选择收缩至: ,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了。
方法二:有一定的风险性,因为软件的日志文件不是即时写入数据库主文件的,如处理不当,会造成数据的损失。
1、删除LOG
分离数据库 企业管理器->服务器->数据库->右键->分离数据库
2、删除LOG文件
附加数据库 企业管理器->服务器->数据库->右键->附加数据库
此法生成新的LOG,大小只有500多K。
注意:建议使用第一种方法。
如果以后,不想要它变大。
SQL2000下使用:
在数据库上点右键->属性->选项->故障恢复-模型-选择-简单模型。
或用SQL语句:alter database 数据库名 set recovery simple
另外,数据库属性有两个选项,与事务日志的增长有关:
Truncate log on checkpoint
(此选项用于SQL7.0,SQL 2000中即故障恢复模型选择为简单模型)
当执行CHECKPOINT 命令时如果事务日志文件超过其大小的70% 则将其内容清除在开发数据库时时常将此选项设置为True
定期对数据库进行检查当数据库文件或日志文件的未用空间超过其大小的25%时,系统将会自动缩减文件使其未用空间等于25% 当文件大小没有超过其建立时的初始大小时不会缩减文件缩减后的文件也必须大于或等于其初始大小对事务日志文件的缩减只有在对其作备份时或将Truncate log on checkpoint 选项设为True 时才能进行。
注意:一般立成建立的数据库默认属性已设好,但碰到意外情况使数据库属性被更改,请用户清空日志后,检查数据库的以上属性,以防事务日志再次充满。
SQL Server 2005如何对表进行分区
一、指定分区列和Compression一样,在软件中也提供了分区的向导界面。在企业管理器中,需要分区的表上右键选择Storage-》Create Partition,这里会列出该表所有的字段,包括字段类型、长度、精度及小数位数的信息,可以选择其中的任意一一列作为分区列(Patitioning Column),不仅仅是数字或者日期类型,即使是字符串类型的列,也可以按照字母顺序进行分区。而以下类型的列不可用于分区:text、ntext、image、xml、timestamp、varchar(max)、nvarchar(max)、varbinary(max)、别名、hierarchyid、空间索引或 CLR 用户定义的数据类型。此外,如果使用计算列作为分区列,则必须将该列设为持久化列(Persisit)。
在列表下方,提供了两个选项:
分配到可用分区表: 这要求在同一数据库下有另一张已分好区的表,同时该表的分区列和当前选中的列的类型完全一致。 这样的好处是当两张表在查询中有关联时,并且其关联列就是分区列时,使用同样的分区策略会更有效率。
将非唯一索引和唯一索引的存储空间调整为与索引分区列一致: 这样会将表中的所有索引也一同分区,实现“对齐”。这是一个重要而麻烦的选项,具体需求请参阅MSDN(已分区索引的特殊指导原则)。 这样的好处是表和索引的分区一致,一方面查询时利用索引更为高效,而且在下文提到的移入移出分区也会更为高效。
注意:这里建议使用聚集索引列作为分区列。一方面索引结构本身就应与查询相关,那么分区列与索引一致会保证查询的最大效率;另一方面,保证索引对齐而且是聚集索引对齐是保证分区的移入移出操作顺畅的前提,否则可能会出现无法移入移出的情况,而分区的移入移出又是管理大数据的重要策略——滑动窗口(SlideWindow)策略的基础操作。
二、分区函数与分区方案选好分区列后,如果没有应用“分配到可用分区表”选项,接下来则会进入选择创建分区函数以及分区方案的界面。其中分区函数会指定分区边界,而分区方案则规划了每个分区所存储的文件组。向导操作界面如下:
其中Left boundary说明每个分区的边界值被包含在边界值左侧的分区中,也就是每个分区内的数据约束是<=指定的边界值,相应的,Right boundary则说明每个分区的边界值被包含在边界值右侧的分区中,每个分区内的数据约束是<指定的边界值。
在下方的列表中,列出了当前分区方案下现有的分区。其中文件组(Filegroup)指定了每个分区存放的位置,如果将分区放置于位于不同磁盘中的不同文件组中,由于不同磁盘的读写互不干扰,这将提高分区表并行处理的效率。一般情况下,将所有分区放置在同一个文件组是比较稳妥的做法。
注意,在这里最后一个分区是没有指定边界的,用于保存所有>(Left Boundary)或>=(Right boundary)最后一个分区边界的数据。
如果选择时间类型的字段作为分区列,可以通过Set按钮实现按条件分组:
这样可以很方便得通过设置起止时间将表按照指定时间段自动分区,但之后依然需要手动指定每个分区的文件组。
制定好分区方案之后可以通过Estimate sotrage预估每个分区的行数、空间占用情况,不过除非需要以占用空间或行数来规划你的分区策略,一般不建议在这里进行预估,因为如果对空表来说,预估的结果当然都是0,而如果表中已经包含大量数据,预估则会花费比较长的时间。
三、创建分区通过以上设置,分区已经基本完毕,在向导的最后,可以选择是创建脚本还是立即执行分区操作。我们可以查看在不同情况下创建分区的脚本的情况:
1.在表没有索引的情况下:
BEGIN TRANSACTIONCREATE PARTITION FUNCTION [TestFunction](datetime) AS RANGE LEFT FOR VALUES(N'2010-01-01T00:00:00', N'2010-02-01T00:00:00', N'2010-03-01T00:00:00', N'2010-04-01T00:00:00', N'2010-05-01T00:00:00', N'2010-06-01T00:00:00')CREATE PARTITION SCHEME [TestScheme] AS PARTITION [TestFunction] TO ([PRIMARY],[PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY])CREATE CLUSTERED
INDEX[ClusteredIndex_on_TestScheme_634025264502439124] ON [dbo].[Account] ( [birthday])WITH(SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON[TestScheme]([birthday])DROP INDEX
[ClusteredIndex_on_TestScheme_634025264502439124] ON [dbo].[Account] WITH ( ONLINE = OFF )COMMIT TRANSACTION
这里先创建Partition Function以及Partition Scheme,之后在分区列上创建聚集索引并按照分区方案分区,最后删除了这一索引。
2.在表有索引的情况下:
如果原先没有聚集索引:
CREATE CLUSTERED INDEX [ClusteredIndex_on_TestScheme_634025229911990663] ON [dbo].[Account] ( [birthday])WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF)ON [TestScheme]([birthday])DROP INDEX [ClusteredIndex_on_TestScheme_634025229911990663] ON[dbo].[Account] WITH ( ONLINE = OFF )
这和没有索引的情况一样,如果表原先存在聚集索引,则脚本变为:
CREATE CLUSTERED INDEX [IX_id] ON [dbo].[Account] ( [id] ASC)WITH (PAD_INDEX = OFF,STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING =ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [TestScheme]([birthday])
可以看到原有的聚集索引(IX_id)在分区方案上被重建了。
如果选择了“对齐索引”选项,则会对所有索引都应用分区:
CREATE CLUSTERED INDEX [IX_id] ON [dbo].[Account] ( [id] ASC)WITH (PAD_INDEX = OFF,STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING =ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [TestScheme]([birthday])CREATE NONCLUSTERED INDEX [UIX_birthday] ON [dbo].[Account] ( [birthday] ASC)WITH(PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY =OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [TestScheme]([birthday])CREATE NONCLUSTERED INDEX [UIX_name] ON [dbo].[Account] ( [name] ASC)WITH(PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY =OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
这里不仅对聚集索引IX_id进行了分区,也对非聚集索引UIX_name和UIX_birthday进行了分区。
PS:对一张表分好区后不可以进行再次分区,同时也没有直接取消表分区的方法。
如果要查看已分区表的分区状态以及每个分区中的行数和占用空间,可以通过Storage-》Management Compression查看。同时可以在这里为每个分区指定压缩方式。
如果分区表索引没有对齐,则不可以对该表进行切入切出(Switch in/out)操作,同样也不能执行滑动窗口操作。
分区实际上是在每个分区表都添加了约束,相应的插入操作的性能也会受到影响。
即使进行了分区,如果查询的条件字段和分区列并没有关联,性能也未必会得到提升。
功能特性
一、构建、部署和管理企业应用程序,使其更加安全、伸缩性更强和更可靠。
二、降低开发和支持数据库应用程序的复杂性,实现了 IT 生产力的最大化。
三、能够在多个平台、应用程序和设备之间共享数据,更易于连接内部和外部系统。
四、在不牺牲性能、可用性、可伸缩性或安全性的前提下有效控制成本。
SQL Server 2005软件功能
1、数据库引擎数据库引擎是用于存储、处理和保护数据的核心服务。利用数据库引擎可控制访问权限并快速处理事务,从而满足企业内要求极高而且需要处理大量数据的应用需要。
使用数据库引擎创建用于联机事务处理或联机分析处理数据的关系数据库。这包括创建用于存储数据的表和用于查看、管理和保护数据安全的数据库对象(如索引、视图和存储过程)。
2、Analysis ServicesAnalysis Services 是一种核心服务,可支持对业务数据的快速分析,以及为商业智能应用程序提供联机分析处理 (OLAP) 和数据挖掘功能。
OLAP
使用 Analysis Services,可以设计、创建和管理包含来自多个数据源的详细数据和聚合数据的多维结构,其中这些数据源(如关系数据库)都存在于内置计算支持的单个统一逻辑模型中。Analysis Services 为根据统一的数据模型构建的大量数据提供快速、直观、由上至下的分析,这样可以采用多种语言和货币向用户提供数据。Analysis Services 使用数据仓库、数据集市、生产数据库和操作数据存储区,以支持历史数据和实时数据分析。
3、数据挖掘Analysis Services 包含创建复杂数据挖掘解决方案所需的功能和工具。
①一组行业标准数据挖掘算法。
②数据挖掘设计器,可用于创建、管理和浏览挖掘模型,并可以根据挖掘模型创建预测。
③DMX 语言,可用于管理挖掘模型和创建复杂的预测查询。
可以组合使用这些功能和工具,以发现数据中存在的趋势和模式,然后使用这些趋势和模式对业务难题作出明智决策。
4、Integration Services软件的提取、转换和加载 (ETL) 组件。它取代了早期的 SQL Server ETL 组件 Data Transformation Services (DTS)。
Integration Services 是用于生成企业级数据集成和数据转换解决方案的平台。使用 Integration Services 可解决复杂的业务问题,方法是复制或下载文件,发送电子邮件以响应事件,更新数据仓库,清除和挖掘数据以及管理对象和数据。这些包可以独立使用,也可以与其他包一起使用以满足复杂的业务需求。Integration Services 可以提取和转换来自多种源(如 XML 数据文件、平面文件和关系数据源)的数据,然后将这些数据加载到一个或多个目标。
Integration Services 包含一组丰富的内置任务和转换、用于构造包的工具以及用于运行和管理包的 Integration Services 服务。可以使用 Integration Services 图形工具来创建解决方案,此时无需编写一行代码;也可以对 Integration Services 对象模型进行编程,通过编程方式创建包并编写自定义任务以及其他包对象的代码。
5、复制复制是一组技术,用于在数据库间复制和分发数据和数据库对象,然后在数据库间进行同步操作以维持一致性。使用复制可以将数据通过局域网、广域网、拨号连接、无线连接和 Internet 分发到不同位置以及分发给远程用户或移动用户。提供以下三种功能各不相同的复制类型:事务复制、合并复制和快照复制。
事务复制通常用于需要高吞吐量的服务器到服务器方案(包括:提高伸缩性和可用性、数据仓库和报告、集成多个站点的数据、集成异类数据以及卸载批处理)。合并复制主要为可能存在数据冲突的移动应用程序或分步式服务器应用程序而设计的。常见应用场景包括:与移动用户交换数据、POS(消费者销售点)应用程序以及集成来自多个站点的数据。快照复制用于为事务性复制和合并复制提供初始数据集;在适合数据完全刷新时也可以使用快照复制。利用这三种复制,提供功能强大且灵活的系统,以便使企业范围的数据同步。
6、Reporting Services是基于服务器的报表平台,提供来自关系和多维数据源的综合数据报表。Reporting Services 包含处理组件、一整套可用于创建和管理报表的工具和允许开发人员在自定义应用程序中集成和扩展数据和报表处理的应用程序编程接口 (API)。生成的报表可以基于Analysis Services、Oracle 或任何 Microsoft .NET Framework 数据访问接口(如 ODBC 或 OLE DB)提供的关系数据或多维数据。
利用 Reporting Services,可以创建交互式报表、表格报表或自由格式报表,可以根据计划的时间间隔检索数据或在用户打开报表时按需检索数据。Reporting Services 还允许用户基于预定义模型创建即席报表,并且允许通过交互方式浏览模型中的数据。所有报表可以按桌面格式或面向 Web 的格式呈现。您可以从许多查看格式中进行选择,以数据操作或打印的首选格式按需呈现报表。
Reporting Services 是基于服务器的解决方案,因此通过它可以集中存储和管理报表,安全地访问报表、模型和文件夹,控制报表的处理和分发方式,并使报表在企业内的使用方式标准化。
7、Notification Services用于开发生成并发送通知的应用程序的平台,也是运行这些应用程序的引擎。可以使用 Notification Services 生成并向大量订阅方及时发送个性化的消息,还可以向各种各样的应用程序和设备传递消息。
使用 Notification Services 平台,可以开发功能齐全的通知应用程序。订阅表达了订阅方在特定信息(称为事件)方面的兴趣,可以根据事件的到达或计划对其进行评估。事件数据本身可以源自数据库内部、其他数据库或外部源。通知是事件和订阅匹配的结果,在发送给订阅方之前,可以采用各种格式。
Notification Services 引擎与数据库引擎协同工作。数据库引擎存储应用程序数据,并执行事件和订阅之间的匹配。Notification Services 引擎控制数据流和数据处理,并且可以扩展到多台计算机。这可以改进要求极高的应用程序的性能。
8、全文搜索全文查询可以包括字词和短语,或者一个字词或短语的多种形式。使用全文搜索可以快速、灵活地为存储在数据库中的文本数据的基于关键字的查询创建索引。在软件中,全文搜索提供企业级搜索功能。
使用全文搜索可以同时在多个表的多个字段中搜索基于字符的纯文本数据。对大量非结构化的文本数据进行查询时,使用全文搜索获得的性能优势会得到充分的表现。例如,对数百万行文本数据执行的 Transact-SQL LIKE 查询可能需要花费几分钟时间才能返回结果;但对同样的数据,全文查询只需要几秒或更少的时间,具体取决于返回的行数。可以对存储在 char、varchar 或 nvarchar 列中的数据或存储在 varbinary(max) 或 image 列中的格式化二进制数据(如 Microsoft Word 文档)创建全文搜索。
9、Service Broker为消息和队列应用程序提供数据库引擎本地支持。这使开发人员可以轻松地创建使用数据库引擎组件在完全不同的数据库之间进行通信的复杂应用程序。开发人员可以使用 Service Broker 轻松生成可靠的分布式应用程序。
使用 Service Broker 的应用程序开发人员无需编写复杂的内部通信和消息,即可跨多个数据库分发数据工作负荷。由于 Service Broker 处理会话上下文中的通信路径,所以降低了开发和测试工作。同时还提高性能。例如,支持网站的前端数据库可以记录信息并将处理密集型任务发送到后端数据库以进行排队。Service Broker 确保在事务上下文中管理所有任务以确保可靠性和技术一致性。
主要特性
1、高性能设计,可充分利用WindowsNT的优势。
2、系统管理先进,支持Windows图形化管理工具,支持本地和远程的系统管理和配置。
3、强壮的事务处理功能,采用各种方法保证数据的完整性。
4、支持对称多处理器结构、存储过程、ODBC,并具有自主的SQL语言。 SQLServer以其内置的数据复制功能、强大的管理工具、与Internet的紧密集成和开放的系统结构为广大的用户、开发人员和系统集成商提供了一个出众的数据库平台。
SQL Server 2005新功能
1、数据库引擎默认情况下,在运行的服务器上使用 DBCC CHECKDB、DBCC CHECKALLOC、DBCC CHECKTABLE 或 DBCC CHECKFILEGROUP 命令时,会显示所有的错误消息。无论是指定或者省略了 ALL_ERRORMSGS 选项,它都不起作用。在早期版本中,如果不指定 ALL_ERRORMSGS,则对于每个对象,只显示前 200 条错误消息。
2、Notification Services此组件发行版支持针对数据库引擎或数据库引擎实例运行Notification Services。
3、复制更新了 sp_showpendingchanges 存储过程,添加了新的参数 @show_rows。此参数可以帮助确定订阅服务器挂起的更改。
4、Reporting Services①支持创建基于 Teradata 数据库的报表模型。通过使用 Business Intelligence Development Studio 中的模型设计器和报表管理器,可以生成基于运行版本 12.00 或版本 6.20 的 Teradata 数据库的报表模型。有关详细信息,请参阅创建和使用基于 Teradata 的报表模型。
②对 PDF 呈现扩展插件进行了更改,支持 ANSI 字符,并且可以从日语、朝鲜语、繁体中文、简体中文、西里尔语、希伯来语和阿拉伯语转换 Unicode 字符。如果可能,PDF 呈现扩展插件现在会将显示报表所需的每个字体的子集嵌入到 PDF 文件中。有关详细信息,请参阅针对 PDF 输出进行设计。
③与本机模式相比,在 SharePoint 集成模式中运行报表通常要慢一些。这一滞后时间主要是由于 SharePoint 对象模型调用导致的。
软件特色
1、真正的客户机/服务器体系结构。
2、图形化用户界面,使系统管理和数据库管理更加直观、简单。
3、丰富的编程接口工具,为用户进行程序设计提供了更大的选择余地。
4、与Windows NT完全集成,利用了NT的许多功能,如发送和接受消息,管理登录安全性等。也可以很好地与Microsoft BackOffice产品集成。
5、具有很好的伸缩性,可跨越从运行Windows 95/98的小型电脑到运行Windows 2000的大型多处理器等多种平台使用。
6、对Web技术的支持,使用户能够很容易地将数据库中的数据发布到Web页面上。
7、提供数据仓库功能,这个功能只在Oracle和其他更昂贵的DBMS中才有。
与以前版本相比较,又具有以下新特性 :
1.支持XML(Extensive Markup Language,扩展标记语言)。
2.强大的基于Web的分析。
3.支持OLE DB和多种查询。
4.支持分布式的分区视图。
软件优势
NET框架主机
XML技术
ADO. NET2.0版本
增强的安全性
Transact-SQL的增强性能
SQL服务中介
通告服务
Web服务
报表服务
全文搜索功能的增强
语言运用
SQL语句可以用来执行各种各样的操作,例如更新数据库中的数据,从数据库中提取数据等。目前,绝大多数流行的关系型数据库管理系统,如Oracle,Sybase,Access等都采用了SQL语言标准。虽然很多数据库都对SQL语句进行了再开发和扩展,但是包括Select,Insert,Update,Delete,Create,以及Drop在内的标准的SQL命令仍然可以被用来完成几乎所有的数据库操作。
安装失败
在安装SQLSERVER2005之前的注意事项,上文有详细的说明,这里就不细讲了。
a、安装IIS,打开控制面板,点“添加或删除程序”,点“添加/删除Windows组件(A)”,
把“Internet 信息服务(IIS)”前面的勾选框的勾选上,点“下一步”,一路确认完成。(此步骤需要将WINXP安装盘放入光驱或用虑拟光驱加载WINXP.ISO文件)
b、安装.Net Framework3.5,当然SQL也会装,但是为了安全起见提前安装是有好处的。
点击“服务器组件、工具、联机丛书和示例(C)
然后一直下一步,直到:
注意:下面这一步,至少要把第一项选中,如果还想在用中查看帮助信息,则要将最后一项选中,其它的选项视情况可选中!建议点击高级选项把安装路径改到D盘
这里最好不要选默认实例,如果你原来机器上有,你选了默认的实例后,将会指向的实例,这样会对后续使用SQL2005很不利,如果没有安装sql 就选择默认,记住默认的就是最好的。
默认实例下,由于安装vs2005时默认安装了sqlserver2005 express所以无法安装,将出现以下画面。直接点击下一步
下面这一步一定要选择混合模式!!!
然后就是下一步等等,直到安装成功
注意:如果在安装过程中没有点击“高级”选项,就会出现下面这一情况
安装完成:
如果上述操作不出现什么意外的话,就可以直到完成了。
安装完数据库后还需要打一个补丁SQLServer2005SP3,
下载前记得看清你的系统是32位还是64位的。
下载后直接点击安装,基本是傻瓜似的安装,记住默认的就是最好的。
重启下电脑,就可以运行了
配置要求
安装、运行的硬件需求1、计算机
Intel及其兼容计算机,Pentium 166Mz或者更高处理器或DEC Alpha和其兼容系统。
2、内存(RAM)
企业版最少64G内存,其他版本最少需要32G内存,建议使用更多的内存。
3、硬盘空间
完全安装(Full)需要180G的空间,典型安装(Typical)需要170G的空间,最小安装(Minimum)需要65G的空间。
SQL Server 2005支持的操作系统
Windows 7, Windows Server 2003, Windows Server 2008, Windows Server 2008 R2, Windows Vista, Windows XP
1、32 位系统 (x86)
具有 Intel Pentium III 600 MHz(或同等性能的兼容处理器)或更高处理器(建议使用 1 GHz 或速度更快的处理器)的 PC
2、64 位系统(x64、ia64)
1 GHz 或速度更快的处理器
最低 512 MB 的 RAM(建议使用 1 GB 或更高的 RAM)
675 MB 的可用硬盘空间
注意:软件的设计宗旨是在 Windows Vista 和 Windows Server 2008 上运行。
点击星星用来评分