ibm spss modeler 18是和IBM SPSS Statistics是同一个公司的数据挖掘、预测分析软件,它的图形界面非常简单但是高级分析能力却是很强很大的,能够轻易的发现结构化和非结构化数据中的趋势,帮助企业或者分析师得到深入的了解和预测。在18这个新的版本中,它新增加了自定义对话框构建程序、“时间序列”节点、扩展主数据中心等等功能,让用户使用的更加得心意手。本站提供
spss modeler 18 破解版下载,并附有安装破解教程!
安装破解教程
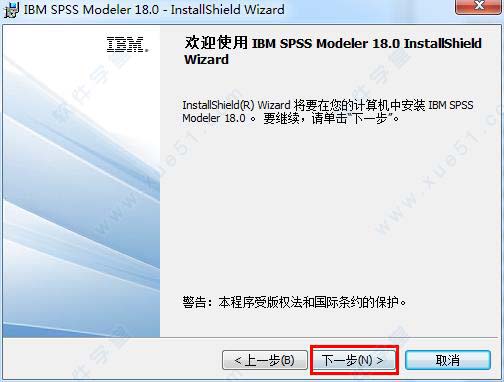
1、在本站下载好软件安装包,先双击运行“1 SPSS_Modeler_18(bit64)”文件夹下的“setup.exe”程序,然后连续点击“下一步”开始安装软件。
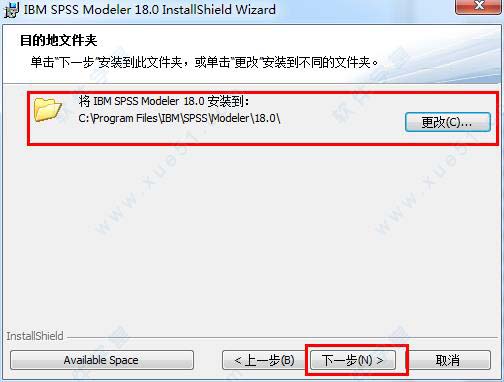
2、到了选择安装目录的位置,建议不要修改,后面要使用到。
3、安装完成,由于我们先是不需要启动的,所以把勾去掉,点击“完成”。

4、然后再去“2 SPSS_Modeler_18_Premium(bit64)”文件夹中双击运行“setup.exe”,中间的安装过程非常简单,根据安装指示来即可。

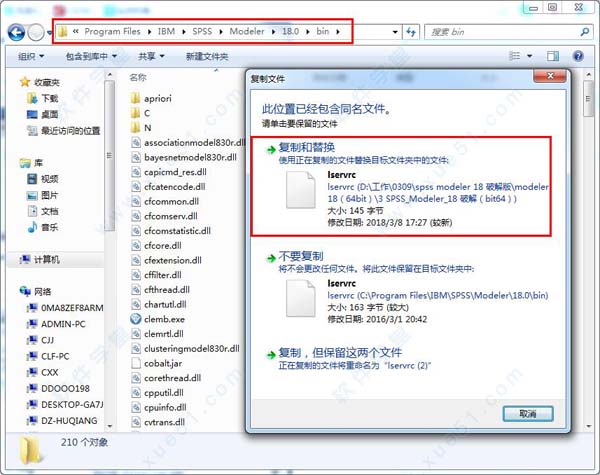
5、到此安装完成,下面开始破解,将“3 SPSS_Modeler_18 破解(bit64)”里面的“lservrc”文件复制到软件的安装目录下面,将原文件覆盖,默认的安装目录为“C:\Program Files\IBM\SPSS\Modeler\18.0\bin”。
6、然后在开始菜单栏中的“Modeler 18.0”文件夹下双击运行“Modeler 18.0”程序即可使用spss modeler 18 破解版。
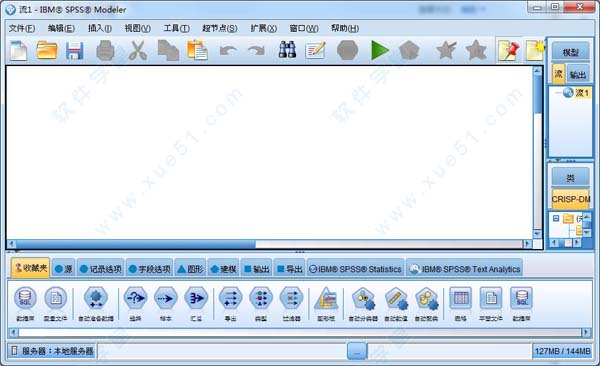
新手使用指导
一、节点节点代表要对数据执行的操作。
例如,假定您需要打开某个数据源、添加新字段、根据新字段中的值选择记录,然后在表中显示结果。在这种情况下,您的数据流应由以下四个节点组成:
 二、数据流
二、数据流该软件进行的数据挖掘重点关注通过一系列节点运行数据的过程,我们将这一过程称为数据流。也可以说这款软件是以数据流为驱动的产品。这一系列节点代表要对数据执行的操作,而节点之间的链接指示数据的流动方向。如,上面提到的四个节点可以创建如下数据流:
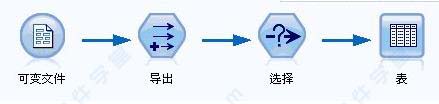
通常,这款软件将数据以一条条记录的形式读入,然后通过对数据进行一系列操作,最后将其发送至某个地方(可以是模型,或某种格式的数据输出)。使用 SPSS Modeler 处理数据的三个步骤:
1、将数据读入 SPSS Modeler。
2、通过一系列操纵运行数据。
3、将数据发送到目标位置。
在 这款软件 中,可以通过打开新的数据流来一次处理多个数据流。会话期间,可以在 SPSS Modeler 窗口右上角的流管理器中管理打开的多个数据流。
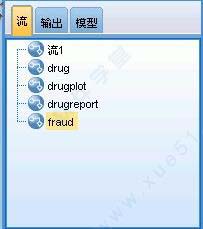 三、节点选项板
三、节点选项板节点选项板位于流工作区下方窗口的底部。

每个选项板选项卡均包含一组不同的流操作阶段中使用的相关节点,如:
1、源:此类节点可将数据导入 SPSS Modeler,如数据库、文本文件、SPSS Statistics 数据文件、Excel、XML 等。
2、记录选项:此类节点可对数据记录执行操作,如选择、合并和追加等。
3、字段选项:此类节点可对数据字段执行操作,如过滤、导出新字段和确定给定字段的测量级别等。
4、图形:此类节点可在建模前后以图表形式显示数据。图形包括散点图、直方图、网络节点和评估图表等。
5、建模:此类节点可使用该软件中提供的建模算法,如神经网络、决策树、聚类算法和数据排序等。
6、数据库建模:节点使用 Microsoft SQL Server、IBM DB2 和 Oracle 数据库中可用的建模算法直接在数据库里进行建模及评估。
7、输出:节点生成数据、图表和可在 SPSS Modeler 中查看的模型等多种输出结果。
8、导出:节点生成可在外部应用程序(如 IBM SPSS Data Collection 或 Excel)中查看的多种输出。
9、IBM SPSS Statistics:节点将 IBM SPSS Statistics 数据导入或导出为 SPSS Statistics 数据,以及运行 SPSS Statistics 提供的功能。
随着对这款软件的熟悉,您可以在收藏夹自定义常用的选项板内容。
四、使用节点和流要将节点添加到工作区,请在节点选项板中双击图标或将其拖放到工作区。已添加到流工作区的节点在连接之前不会形成数据流,可以将各个图标连接以创建一个表示数据流动的流,节点之间的连接指示数据从一项操作流向下一项操作的方向。
这款软件中最常见的鼠标用法如下所示:
1、单击:使用鼠标左键或右键选择菜单选项,打开上下文相关菜单以及访问其他各种标准控件和选项。单击节点并按住按键可拖动节点。
2、双击:双击鼠标左键可将节点置于流工作区,编辑工作区现有节点。
3、中键单击:单击鼠标中键并拖动光标可在流工作区中连接节点。双击鼠标中键可断开某个节点的连接。如果没有三键鼠标,可在单击并拖动鼠标时通过按 Alt 键来模拟此功能。
创建了流以后,可以对流进行保存、添加注解,将其添加到工程。从文件主菜单中,选择流属性还可以为流设置各种选项,如优化、日期和时间设置、参数和脚本。使用流属性对话框中的消息选项卡,可以轻松查看有关运行、优化和模型构建和评估所用时间等流操作有关的消息,流操作的错误消息也将在这里报告。
五、SPSS Modeler 管理器可以使用流选项卡打开、重命名、保存和删除在会话中创建的多个流。
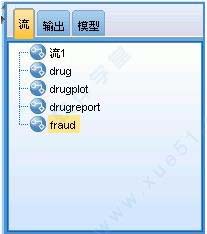
输出选项卡中包含由 SPSS Modeler 中的流操作生成的输出或图形文件。您可以显示、保存、重命名和关闭此选项上列出的表格、图形和报告。

模型选项卡是管理器选项卡中功能最强大的选项卡。该选项卡中包含所有模型块,如当前会话中生成的模型,通过 PMML 导入的模型等。这些模型可以直接从模型选项卡上浏览或将其添加到工作区的流中进行数据分析。

窗口右侧底部是工程工具,用于创建和管理数据挖掘工程(与数据挖掘任务相关的文件组)。有两种方式可查看您在 SPSS Modeler 中创建的工程 - 类视图或 CRISP-DM 视图。
依据跨行业数据挖掘过程标准 CRISP-DM选项卡提供了一种组织工程的方式。不论是有经验的数据挖掘人员还是新手,使用 CRISP-DM 工具都会使您事半功倍。
类选项卡提供了一种在 SPSS Modeler 中按类别(按照所创建对象的类别)组织您工作的方式。此视图在获取数据、流、模型的详尽目录时十分有用。
新增功能
1、“时间序列”节点
这款软件提供新的“时间序列”节点。新节点类似于前发行版中提供的“时间序列”节点,但其在运行时带有嵌入式或远程 IBM SPSS Analytic Server,用于处理大数据并在输出查看器中显示生成的模型。此外,还提供基于新“时间序列”节点的新“流式时间序列”节点。
注:已不推荐使用先前的“时间序列”节点、“流式时间序列”节点和“时间间隔”节点;但是,其功能在任何现有流中仍受支持。
2、扩展主数据中心
已添加新的扩展主数据中心(从 SPSS Modeler Client 中的扩展 > 扩展主数据中心进行访问)。扩展主数据中心是一个界面,用于从 GitHub 上的 IBM SPSS Predictive Analytics 集合中搜索、下载和安装扩展。有关详细信息,请参阅 IBM SPSS Modeler 扩展文档。
3、自定义对话框构建程序
已对自定义对话框构建程序进行大量改进并向其添加增强功能。有关更多信息,请参阅扩展文档。
4、Modeler Server 上的 Python Spark
在 V17.1 中,针对 IBM SPSS Analytic Server 运行时添加了 Python Spark 支持(先前仅支持 R)。现在,还支持Modeler Server。有关更多信息,请参阅 SPSS Modeler 扩展文档。
核心亮点
1、访问各种数据源,如数据仓库、数据库、 Hadoop 分布或平面文件,以便从您 的数据中发现隐含的模式
2、在影响点即时向工作人员和系统提供具 有预测性、资源敏感和战略一致的决策
3、不论统计或分析背景如何,让可从分析 受益的人掌握分析
4、这款软件利用设计用于处理从简单的描述性分析 问题到最复杂的优化问题的单一平台, 解决业务问题
5、利用数据库内性能和最小化的数据移动, 在更短时间内分析大量数据,同时充分 利用现有 IT 投资
6、利用可在
大多数环境中部署并与其他 IBM 解决方案集成的开放平台,弥合 分析和行动之间的差距。
脚本编写的常用技巧
1、屏蔽文件覆盖的提问:脚本自动执行时不希望中间跳出窗口提问是否覆盖文件。这个功能没有对应的脚本命令,只能使用菜单改变该数据流的用户选项 (Tools...Options...User Options),不选 Warn when a node overwrites a file。
2、调试方法:没有提供调试功能,只能点击按钮 Run selected lines only,选择部分脚本运行。
3、自动刷新数据源节点:当原始数据改变时,需要刷新对应的数据源节点。使用命令 set ^stream.refresh_source_nodes = True 实现所有数据源节点的自动刷新。
4、屏蔽数据源密码提问:对应通过 ODBC 连接的数据库数据源,数据流自动执行时会提问密码。屏蔽这种提问的命令:set 'Database1':databasenode.password = "mypassword"
5、模型节点的自动更新:不同于鼠标操作,脚本执行建模节点不会自动更新对应的模型节点。需要使用 insert model 命令更新模型。如果需要同时更新多个模型节点,还需使用 duplicate 命令。例如,下列脚本根据建模节点 AutoNumeric 的执行结果,自动更新 Actual2 和 Actual3 两个模型节点:
execute 'AutoNumeric'
insert model Actual2 connected between 'Type2':typenode and 'AFFV_AR_Q1':derivenode
duplicate Actual2 as Actual3 connected between 'Type3':typenode and 'Filter3':filternode
6、清除已有的模型节点:常用命令有三种,注意它们的区别。
delete Actual2 ( 命令 delete NODE) 从工作区上删除模型节点;
clear generated palette 清除管理器上的所有模型节点;
delete model Actual2 清除管理器上而不是删除工作区的模型节点。
7、高级脚本功能需要使用对象 (Object):常用的对象有四种:Output; Node; Model; Result。每类对象都有一些专用的命令用于定义和检索这些对象,例如 get output; execute 'Node1'; export model; value 'Result1' at Row1 Column1。详细命令参见用户指南第四章内容 (Scripting Commands)。例如,根据 Table 节点的输出读取循环变量,就可使用 Result 对象的 value 命令。参见本文“1.1 重复执行的数据处理”一节的实例。
软件特性
SQL 生成与优化
一、配置 IBM SPSS Modeler 以支持SQL生成与优化1、优化 SQL 生成:选中该选项可以对流中的节点进行重新排序,以便将更多的操作提交到数据库中执行。当发现某个节点所执行的操作无法包含到 SQL 中时,该优化选项会向流的后继节点查看,搜索符合条件的后继节点,在不影响流语义的情况下将该后继节点提前至该节点之前。
2、数据库缓存:对于生成 SQL 的流,数据可以在流的中间某个节点缓存到数据库而不是文件系统临时表中。如果与 SQL 优化相结合,则此操作将使性能得到显著提高。例如,可以对合并多个表以创建数据挖掘视图的流的输出进行缓存并在需要时重新使用。启用数据库缓存后,在需要缓存数据的非终端节点处单击右键,选择打开缓存。下次运行流时,将直接在数据库中自动创建缓存。在使用该选项时,需要确认数据库的策略或权限允许创建并访问临时表空间。
3、日志与状态:将流预览和执行期间生成的 SQL 逐条显示在消息窗口内。对于 SQL 的显示,可以选择使用数据库提供的函数,或者使用标准 ODBC 函数。该选项仅影响 SQL 语句在客户端的显示,与 Modeler 提交给数据库的 SQL 语句无关。以 CLEM 表达式中的 trim 函数(用于去除字符串前、后的空白字符)为例。表 2 给出了连接 DB2 数据库时,使用两种选项得到的 SQL 片段。
 二、构建可生成 SQL 的流
二、构建可生成 SQL 的流1、流文件通常包含源节点,数据操作节点和终端节点。SQL 生成的过程从源节点开始,首先取得数据库表中各个字段的定义,然后经过数据操作节点对字段进行加工,最终将结果集合提交至终端节点显示或存储。因此,SQL 生成的前提之一是源节点必须为数据库节点。如果数据来自文本文件或其他产品(如 Statistics,Data Collection,Cognos 等),可以使用数据库输出节点将数据导入数据库的一张或多张表。
这里,我们将 Modeler 示例文件夹中的 Drug1n 数据取出,增加索引字段并创建名为 Drug1nID 的表。首先插入文件源节点,选择 Drug1n 数据文件并查看字段类型及定义。在文件源节点之后插入导出节点,使用表达式构造器添加索引字段
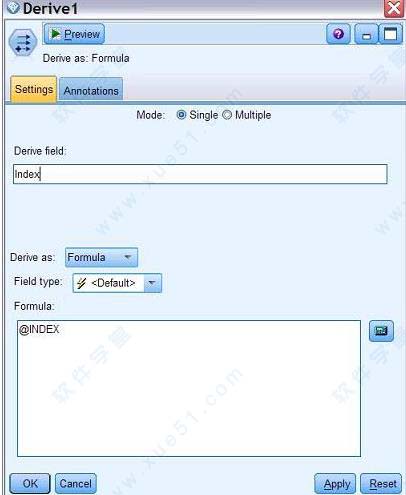
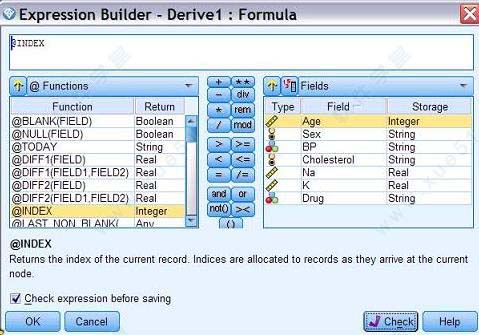
2、表达式构造器可以从导出节点右侧的计算器图标进入。构造器界面左侧为可供选择的函数列表,右侧为可以参与计算的字段和参数。
3、在导出节点之后插入数据库导出节点,指定数据源及表名,将数据导入数据库中指定的表。这里也可以对表的模式及索引进行修改。

4、插入一个数据库源节点,选择数据库并制定上一步创建的表,在“类型”页可以看到各个字段的定义和内容。到此,SQL 生成所需的源节点就创建完成。下一步就是在源节点之后根据需要插入数据操作节点,对数据进行整理和准备,以便数据挖掘。

5、数据操作节点包括两类:施加在整条记录上的记录操作节点和施加在某(几)个字段上的字段操作节点。大部分数据操作节点都能够支持 SQL 生成,具体的节点列表可以在 IBM SPSS Modeler 的在线文档中找到(IBM SPSS Modeler Help -> Server Administration and Performance -> SQL Optimization -> Nodes Supporting SQL Generation)。
这里有两点需要注意。
(1)某些节点的 SQL 生成选项需要在节点参数设置中打开才能支持 SQL 生成。例如 Partition 节点,在该节点设置选项卡的底部,有一个“启用 SQL 以分配记录到分区”的选项,选择该选项并指定具有唯一值的字段,Modeler 就能够生成对应的 SQL 以确保用随机且可重复(需要数据库提供可以接收种子的随机数函数)的方式分配记录。
这里,我们将之前创建的 Drug1nID 表取出,使用索引字段建立分区,生成的 SQL 语句如 清单 1所示。
清单 1. 分区(Partition)节点生成的 SQL 语句片段

(2)在使用 CLEM 表达式对数据进行加工时,由于数据库实现的差异性,并不是所有 CLEM 表达式函数都能够支持 SQL 生成。在线文档里列出了能够支持 SQL 生成的所有函数(IBM SPSS Modeler Help -> Server Administration and Performance -> SQL Optimization -> CLEM Expressions and Operators Supporting SQL Generation)。
功能介绍
1、访问各种类型的数据
借助Modeler 18破解版,您可以使用各种分析技术访问数据源, 如数据仓库、数据库、Hadoop 分布或平面文件,以便从您 的数据中发现隐含的模式。这些统计技术使用历史数据来预 测当前状况或未来事件。这些统计技术还包括数据访问、数 据准备、数据建模和交互可视化功能。借助准备和建模自动 化流程,该产品适用于各种分析能力。
2、通过一系列技术拓宽您的分析范围
借助这款软件,您的分析师可利用设计用于处理简单 的描述性分析问题、最复杂的优化问题以及这两者之间的一 切问题的单一平台,解决业务问题。这款软件具有超 出当今分析师标准分析要求的功能。一系列模型以及自动建 模和数据准备、文本分析、实体分析和社交网络分析功能, 可以帮助您处理最复杂的问题。
3、一系列模型及算法
分类算法-根据历史数据和技术进行预测。分段算法-利用自动聚类、异常检测和聚类神经网络技术 将工作人员进行分组或检测不寻常的模式。关联算法-发现先验、CARMA 和序列关联性的关联、链 接或序列。时间系列和预测-随着时间的推移,利用统计建模技术生成一个或多个系列的预测。可扩展性与 R 编程语言-应用转型,用脚本进行分析, 并用 R 编程语言汇总或生成文本和图形输出。
4、数据准备和操作
该软件使数据准备自动化,以简化流程并帮助您确 保您的数据格式为便于分析的最好格式。自动化任务包括进 行分析数据和识别修复工具,筛选字段,必要时派生新属性, 并通过智能筛选技术提高性能。
5、自动数据建模
借助 SPSS Modeler 这款软件地理空间分析
借助这款软件,您可探索与某个位置有关的各个数 据元素之间的关系并对您的数据进行地理空间分析,以发掘在图表或表格中不可见的洞察力。通过空间挖掘,您可 利用 ESRI shape file 文件轻松挖掘地理空间数据。通过分 析空间数据和非空间数据,可以提高整个模型的准确性, 且您可以获取对人员和事件的更深入洞察力。
7、文本分析
借助可定制 的特定行业文本分析包,您可以对正确的上下文里的除首 字母缩写、表情符号和俚语之外的相关术语和词组进行分 析。交互式图表可帮助您探索和显示文本数据和模式,以 便进行快速分析。
8、实体分析
借助这款软件的实体分析功能,您可非常轻松高效地 将身份、行为和行动数据与各自的实体实时或批量关联起来。 您还可适时合并记录或将它们分离开来。结果会怎样呢?您 的组织将具有可帮助提高模型质量的关联企业数据。
9、社交网络分析
这款软件可提供相关社交网络分析功能,将与关系有 关的信息转为显示个人和团队的社会行为的关键业绩指标。 您可以利用这些指标来识别影响网络中他人行为的社交领导 者。结合这些结果与其他措施,您可以创建全面的个人资料 文件,并以此作为您的预测性模型的基础。
10、借助灵活部署适应您的各种需要
这款软件架构是一个支持一系列平台和语言的开放 式平台。您可以在您的环境中或从云端部署 SPSS Modeler,然后 在您的现有系统中自信地用它来优化性能和处理业务问题。 通过按计划或按要求为工作人员和流程提供结果,这种灵 活部署可弥合分析和行动之间的差距。
11、改善决策和成果
利用各种高级算法构建预测模型。
结合使用预测模型、业务规则和优化技术,在给定参数内通过云执行决策。
在影响点向人员和系统提供建议,改善决策和操作。
将分析结果集成到现有业务流程和运营应用中。
将 SPSS Modeler 与 IBM Cognos Business Intelligence 集成时,在 BI 报表或仪表盘中显示分析
集成 IBM Cognos TM1,以在 Cognos TM1 多维数据集中使用或显示数据。
12、从数据中提取价值
无论数据存储在何处(例如,数据仓库、数据库、平面文件等),均可执行分析。
将这款软件与 IBM SPSS Analytic Server 结合使用时,可在 Hadoop 版本中分析数据。
不仅可分析结构化数据(例如,年龄、价格、产品、位置等),也可以分析非结构化数据(例如,文本、电子邮件、社交媒体数据等)。
使用统计算法和文本分析揭示数据中隐藏的洞察和模式。
使用实体分析进行实体解析和社交网络分析,显示个人和群体的社交行为。
通过自动化的数据准备、建模和基于 Web 的订阅降低复杂性。
13、更轻松地集成到现有系统中
与 IBM 数据库或其他供应商的数据库配合使用,更快速、更高效地部署模型并评分。
通过将 SPSS Modeler 与 SPSS Statistics、Cognos Business Intelligence、Cognos TM1 和 InfoSphere Streams 集成,实现更流畅的分析工作流程。
通过使用那些支持 IBM Pure DataTM Systems、InfoSphere Warehouse、IBM DB2 和 Linux on IBM System z 功能的服务器版本,最小化数据移动,并提高性能。
通过“冠军/挑战者”方法评估预测模型,并自动执行评估。
点击星星用来评分