finereader12是一款OCR光学字符识别系统,通俗简单点说就是将图片上的文字进行识别的软件。通能够将纸质文本、数码照片、pdf格式等多种文件形式的图像文件中的字符进行识别扫描,并且将里面的文字转换成可编辑的格式,再把它们加以调整,创建为可搜索的文档,这样就可以减少重复录入的工作,从而提高员工的工作效率。这个新的版本的abbyy finereader 12中,它创新了后台OCR,给用户更加好的使用界面,并且还提高了表格转换效率和多国语言识别的准确度、将商务文档识别的准确度。软件学堂提供finereader12绿色版与原程序下载,你可直接使用绿色版,也可根据下文附有的安装教程运行原程序进行安装。
安装教程
1、运行“ABBYY_FineReader_Pro_trial.exe”程序。

2、点击“安装ABBYY FineReader 12”。
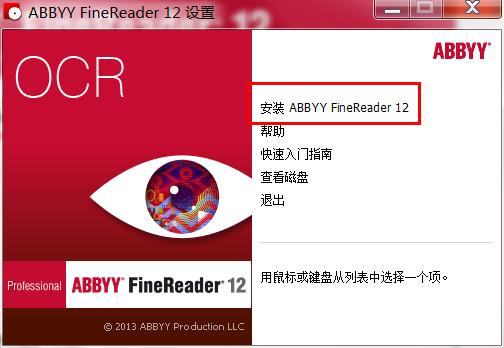
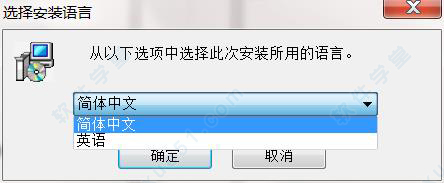
3、根据自己的需求进行语言的选择,然后它自己会跳转到安装界面。
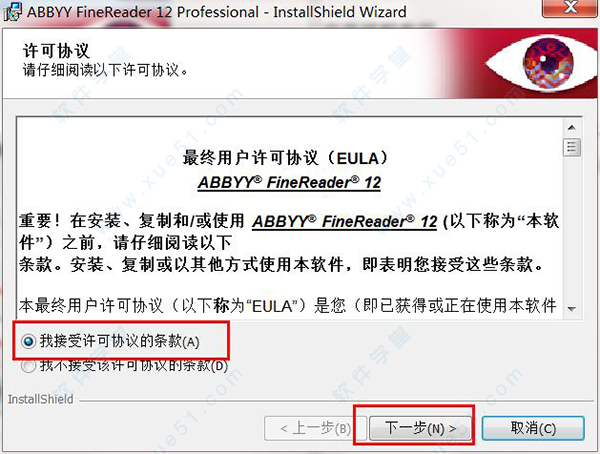
4、勾选“我接受许可协议”,点击“下一步”。
5、安装类型有两种:典型安装和自定义安装,建议选择典型安装,若是专业人士,知道需要软件的那些具体的功能可选择自定义安装。然后选择安装路径,默认的安装目录为:C:Program Files (x86)ABBYY FineReader 12。
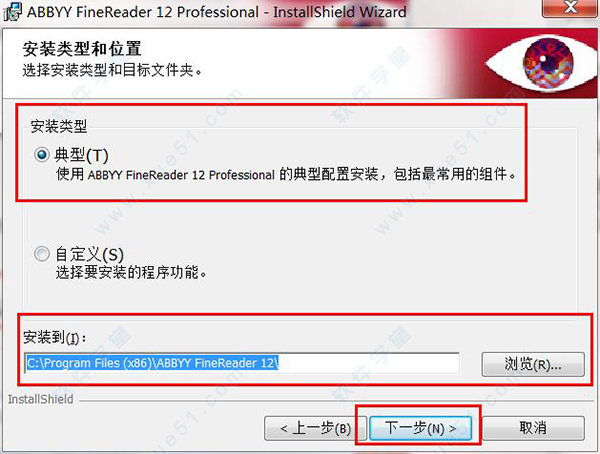
6、正式安装之前,需要选择一些软件的一些项目,可根据自身的需求进行选择,全选或者都不选都不会影响软件的正常使用。
7、安装过程需要几分钟,请耐心等待一会儿。
8、abbyy finereader 12安装完成会有如下图所示的提示,点击“完成”即可。

新功能
一、识别准确率得到提高由于ABBYY专有的适应性文档识别技术(ADRT),新版本的ABBYY FineReader提供更加准确的OCR及对文档原始格式实现更好的重建效果。现在的程序可以更好地检测文档样式、标题和表格。因此,一旦文档被识别,就无需重新调整格式。
二、识别语言finereader12绿色版现在可以识别带重音符号的俄语文本。针对中文、日语、朝鲜语、阿拉伯语和希伯来语的OCR质量得到提高。
三、用户界面更快更友好1、后台处理
识别非常大的文档可能需要花费大量的时间。在新版本中,耗时的进程将在后台运行,以便您可以继续处理文档中已识别的部分。现在,您可以不必等待OCR
进程的完成,即可对图像区域进行调整,查看未识别的页面,强制启动特殊页面或图像页面的OCR进程,从其他来源添加页面或对文档中的页面重新排序。
2、图像加载更快
扫描纸质原件时,页面图像即出现在程序中,因此您可立即查看扫描结果并选择需要识别的图像区域。
3、引用更轻松
只需点击一下鼠标,即可轻松地识别任何包含文本、图片或表格的图像,并复制到剪贴板中。
四、图像预处理和相机OCR改进的图像预处理算法能确保更好地识别拍摄文本,并创建出可与扫描效果相媲美的文本照片。全新的照片校正功能包括自动剪裁、几何失真、夜晚黑暗和背景颜色校正,软件允许您对任何新添加的图像选择所需的预处理选项,以便您不需要对每张图像单独地进行校正。
五、归档文档的显示质量更佳finereader12绿色版 包括新的PreciseScan技术,可以使字符平滑,以提高扫描文档的显示质量。因此,即使您放大页面,字符也不会出现像素化现象。
六、用于手动编辑识别输出的新工具1、新版本中扩展了验证和校正功能。在finereader12绿色版中,可在验证窗口设定已识别文本的格式。现在,还包括一个可插入标准键盘无法输入的特殊符号的工具。您还可以使用快捷键来执行最常用的验证和校正命令。
2、在软件中,您可以禁用诸如页眉、页脚、脚注、目录和编号列表之类的结构元素的重建。当您希望这些元素作为普通文本以便更好地兼容其他产品(如,翻译软件和电子书编写软件)时,这将很有必要。
七、新保存选项1、当将OCR结果保存到XLSX时,您现在可以保存图片、去除文本格式及将每个页面保存到单独的Excel工作表中。
2、软件可创建符合EPUB2.0.1和EPUB3.0标准的ePub文件。
八、与第三方服务和应用程序的集成功能得以改进现在,您可以直接将已识别的文档导出至SharePoint Online和Microsoft Office?365(仅适用于FineReader 12 Corporate),并且新打开和保存对话框提供便捷的云存储服务途径,如Google Drive、Dropbox和SkyDrive。
软件特色
一、准确的OCR图片文字识别技术1、卓越的识别准确度和版本还原
2、高达99.8%的识别准确度 - 将扫描和文档图像转换为可编辑、可搜索的格式并具有卓越的准确度。版面和格式的准确还原 - 特有的适应性文档识别技术(ADRT),智能分析并重新创建多页文档,包括表格、图表和图形。
3、扫描纸质文件和PDF文件OCR
4、轻松扫描纸质文件或PDF转换为可编辑文本,保留原来的布局和格式。
5、从纸张中轻松提取数据并引用在其他文档中,节省手动输入时间。
6、随时从文档变成可搜索的PDF文件,归档和检索信息方便可靠。
7、数码相机OCR
8、提取用智能手机或数码相机拍摄的文件,即可转换成可编辑格式。
9、先进的图像预处理功能加上丰富的手动和自动图像校正编辑工具,确保转换结果的高品质。
二、强大的转换和编辑功能1、转换为可编辑、可搜索的格式
2、扫描的纸质文件、PDF文件和图像等转换成可编辑的格式包括Microsoft Word、Excle、PowerPoint、可检索的PDF、HTML等。
3、finereader12绿色版一键创建可搜索的PDF文件,应用MRC压缩技术优化PDF大小,节省存储资源,并采用PDF/A文件格式,便于长期保存。
4、卓越的转换、结果校验和编辑
5、即时文件访问 - 处理大型、多页文档更加容易,无需预先完成整份文档的转换,即可查看、管理、编辑和提取已识别的区域。
6、便增强的校验向导 - 文本检验更快、更方便,不仅可以检验拼写错误,还可以检验字体格式。
7、内置
文本编辑器-可以编辑识别结果并预览,保存为喜爱的格式。
三、便捷的云同步存储体验1、轻松同步云存储
2、可方便地从云端下载要转换的文件,包括百度云、Google Drive、Dropbox、SkyDrive和SharePoint Online3.等,并可以轻松将识别结果存到云端以备备份和共享。
4、创建电子图书,随时随地享受阅读乐趣
5、EPUB和FB2格式的文章是电子书设备和智能手机的最佳选择,直接发送电子图书到亚马逊账户或用于存档的电子图书馆,即可随时随地阅读。
使用教程
一、基本的使用过程。1、首先打开需要转换的图像或PDF文件,看一下有哪些语言文字;
2、运行软件,在“文档语言”下拉列表中选择“更多语言”;
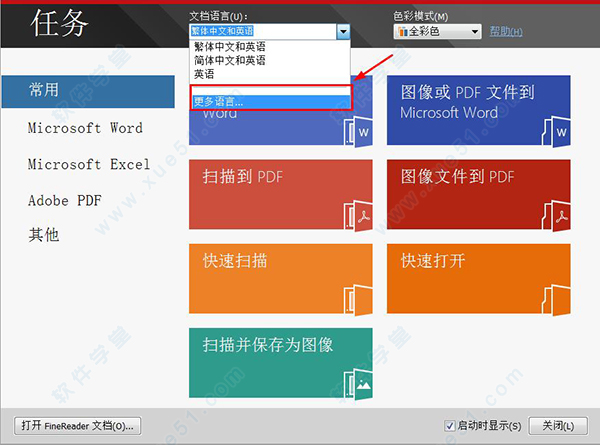
3、在“语言编辑器”中勾选包含的语言“简体中文和英语”,点击“确定”;

4、返回“任务”,点击“快速打开”;
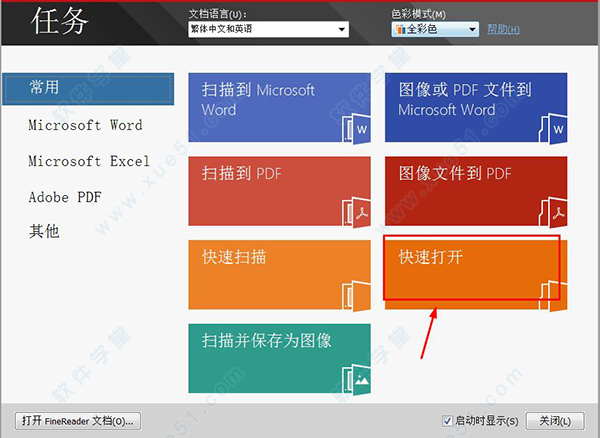
5、弹出“打开图像”对话框,选择需要转换的文件,也可以选择多个文件批量识别转换,例如选择PDF文件,勾选自定义页面范围,输入“5-8”页面识别,然后点击“打开”;

6、在“主工具栏”上点击“读取”,读取所有的未识别的页面;

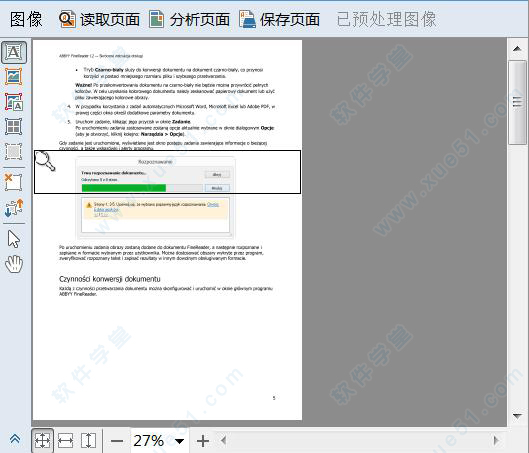
7、finereader12绿色版将自动分析页面不同类型的区域,如文本、图片、背景图片、表格和条形码,在“图像”窗口绘制和调整未能正确识别的检测区域,调整区域之后请再次点击“读取”以识别;
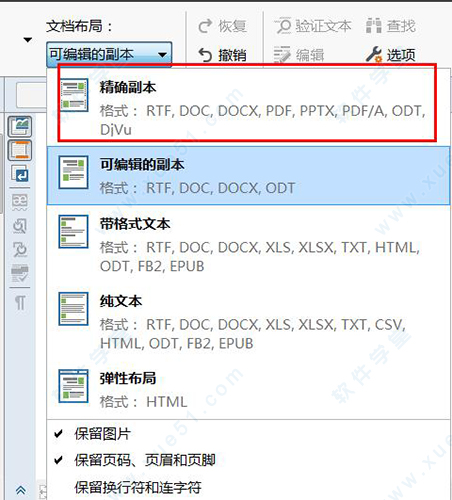
8、如果“文本”窗口识别版面和源文件版面相差太大,在“主工具栏”将“文档布局”选择为“精确副本”;
9、在“文本”窗口会将可能错误的字符以蓝色背景颜色显示出来,便于校对更正,可以右键文字以显示原图像和待选字符,再选择正确字符,对没有正确识别字符直接手动输入更正;
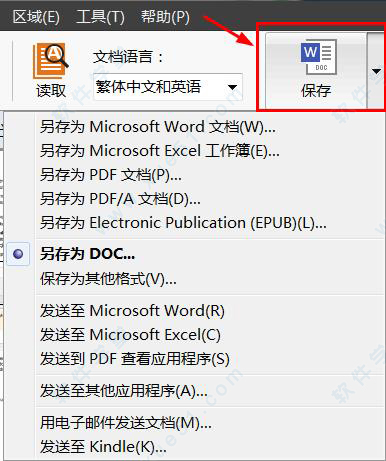
10、校对完成之后,在“主工具栏”上选择“另存为Microsoft Word文档”,或选择菜单“文件”-“将文档另存为”-“Microsoft Word文档”,也可以保存为其他可编辑的格式。
11、以上就是软件转换文本的基本步骤,熟练掌握后便可轻松用来转换需要的文本,既方便了自己的工作,又可以提高工作效率。
二、如何进行文档转换1、在主工具栏上,从文档语言下拉列表中选择文档语言。
2、扫描页面或打开页面图像。
默认情况下,ABBYY FineReader 会自动分析并识别扫描或打开的页面。可以在选项对话框中的扫描/
打开选项卡上更改此默认行为(选择工具 > 选项...打开该对话框)。
3、在图像窗口,查看检测区域并执行必要的调整。
4、如果您调整了任何检测区域,在主工具栏上单击读取以再次识别。
5、在文本窗口,查看识别结果并执行必要的修正。
6、在主工具栏上单击保存按钮右边的箭头并选择保存格式。或者,在文件菜单上单击保存命令。
三、PDF如何转换成EPUB格式1、打开finereader12绿色版,在任务首页上点击‘其他’,然后点击‘图像或PDF文件到EPUB’。
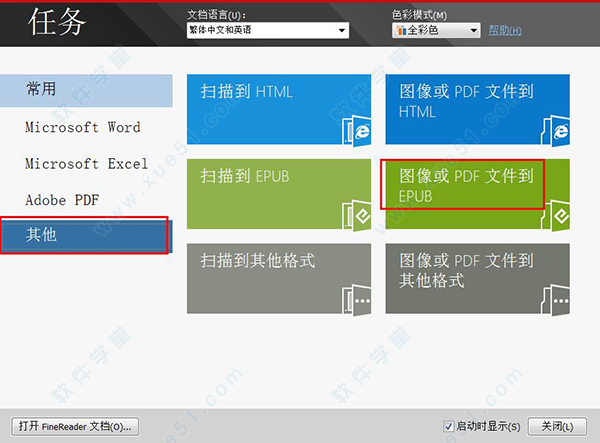
2、在打开图像对话框中选择要转换为EPUB格式的PDF文件。
3、打开PDF文件之后,软件会自动识别文档,等待识别完成。
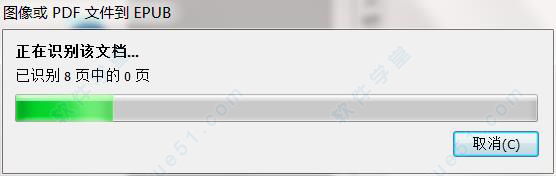
4、完成识别文档之后,自动弹出‘另存为’对话框,在另存为对话框的保存类型下拉列表中,选择Electronic Publication(.epub),然后点击保存;或者在文件选项卡上,点击将文档另存为,在出现的列表中选择Electronic Publication(EPUB)。
提示:步骤四里文档识别完成之后,转换结果会显示在屏幕右侧,建议对照原PDF文件进行校正,看有没有识别错误的地方,PDF文件的质量会影响识别效果,修改之后再进行保存。
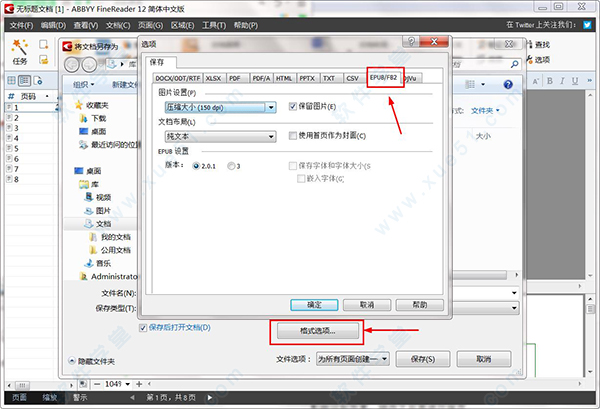 注:在另存为对话框中,还可设置格式,点击“格式选项”按钮,进入选项对话框,进行图片设置和布局设置。
注:在另存为对话框中,还可设置格式,点击“格式选项”按钮,进入选项对话框,进行图片设置和布局设置。
注意:转换后的EPUB电子出版格式,需安装相应的应用程序才能打开。四、finereader12绿色版中怎样禁用自动处理?如果文档包含的文本混合使用了CJK语言和欧洲语言,建议仅在所有页面图像的方向都无误的情况下(例如没有倒置扫描)禁用自动页面方向检测及使用双页拆分选项。
检测页面方向和拆分对页选项可在选项对话框的扫描/打开选项卡上启用和禁用。
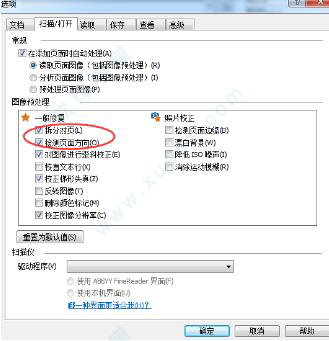 注意:要以阿拉伯语、希伯来语或意第续语拆分对页,请确保首先选择相应的识别语言,然后再选择拆分对页选项,这样便于确保以正确的顺序排列页面。也可以通过选择翻动书本页面选项来恢复原始页面编号。
注意:要以阿拉伯语、希伯来语或意第续语拆分对页,请确保首先选择相应的识别语言,然后再选择拆分对页选项,这样便于确保以正确的顺序排列页面。也可以通过选择翻动书本页面选项来恢复原始页面编号。如果文档的结构复杂,建议禁用对图像执行自动分析和OCR,执行手动操作。
禁用自动分析和OCR步骤如下:
步骤一:打开选项对话框(工具 > 选项);
步骤二:从扫描/打开选项卡上清除在添加页面时自动处理选项。

步骤三:点击确定。
系统要求
1、1 GHz 或更快的 32 位 (x86) 或 64 位 (x64) 处理器
2、Microsoft? Windows? 8、Microsoft? Windows? 7、Microsoft Windows Vista、Microsoft
Windows XP、Microsoft Windows Server 2012/2012 R2、Microsoft Windows Server
2008/2008 R2 或 Microsoft Windows Server 2003
操作系统必须支持您为用户界面选择的语言。
3、1024 MB RAM
在多处理器系统中,每个额外的处理器还需要额外 512 MB RAM。
4、程序安装需要 850 MB 的可用磁盘空间,程序运行需要额外的 700 MB
5、finereader12绿色版支持分辨率为 1024×768 的显卡和显示器
6、键盘和鼠标或其他定位设备

点击星星用来评分